Traduce cualquier idioma en solo 60 líneas de Python.
Traducción a Español de un artículo de Nicolas Bertagnolli, donde nos explica lo mucho que ha avanzado la Traducción Automática en los últimos años, y cómo hoy en día, permite traducir 2 idiomas con sólo 60 líneas de código Python.
 1 julio, 2021 Traducción de idiomas con Python, by Nicolas Bertagnolli
1 julio, 2021 Traducción de idiomas con Python, by Nicolas BertagnolliDescubre cómo usar Python para traducir cualquier idioma en tan solo 60 líneas de código. Como ingeniero de PNL, me voy a quedar sin trabajo pronto 😅.
Disclaimer: Esta es una traducción gratuita de un texto original de Nicolas Bertagnolli realizada gratuitamente por un estudiante de traducción para la empresa de traducción Ibidem Group. Si necesitas servicios de traducción profesional, es mejor que contactes con una agencia de traducción en Madrid o alguna oficina de traducción en Barcelona.
INDICE
Introducción
Recuerdo cuando construí mi primer sistema de traducción seq2seq en 2015. Fue una tonelada de trabajo, desde el procesamiento de los datos hasta el diseño y la implementación de la arquitectura del modelo. Todo eso era para traducir un idioma a otro idioma. Ahora los modelos son mucho mejores y las herramientas en torno a estos modelos también son mejores. HuggingFace ha incorporado recientemente más de 1.000 modelos de traducción de la Universidad deHelsinki a su zoo de modelos de transformación y son buenos. Casi me siento mal haciendo este tutorial porque construir un sistema de traducción es tan sencillo como copiar la documentación de la biblioteca de transformadores.
De todos modos, en este tutorial, haremos un transformador que detectará automáticamente el idioma utilizado en el texto y lo traducirá al inglés. Esto es útil porque a veces estarás trabajando en un dominio donde hay datos textuales de muchos idiomas diferentes. Si construyes un modelo sólo en inglés tu rendimiento se verá afectado, pero si puedes normalizar todo el texto a un solo idioma probablemente lo harás mejor.
💾 Datos 💾
Para explorar la eficacia de este enfoque, necesitaba un conjunto de datos de pequeños tramos de texto en muchos idiomas diferentes. El reto JigsawMultilingualToxicCommentClassification de Kaggle es perfecto para esto. Tiene un conjunto de entrenamiento de más de 223.000 comentarios etiquetados como tóxicos o no en inglés y 8.000 comentarios de otros idiomas en un conjunto de validación. Podemos entrenar un modelo simple en el conjunto de entrenamiento en inglés. A continuación, utilizaremos nuestro transformador de traducción para convertir todos los demás textos al inglés y realizaremos nuestras predicciones utilizando el modelo inglés.
Si echamos un vistazo a los datos de entrenamiento, vemos que hay unos 220.000 textos de ejemplo en inglés* etiquetados en cada una de las seis categorías.
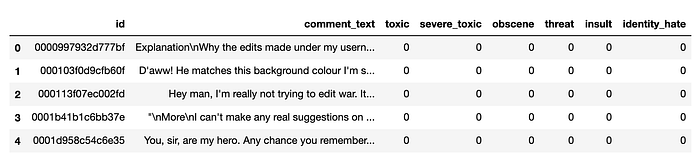
Donde las cosas se ponen interesantes es en los datos de validación. Los datos de validación no contienen inglés y tienen ejemplos de italiano, español y turco.

Ejemplo de datos de validación
🕵️♀️ Identificar el idioma 🕵️♀️
Naturalmente, el primer paso para normalizar cualquier idioma al inglés es identificar cuál es nuestro idioma desconocido. Para ello, recurrimos a la excelente bibliotecaFasttext de Facebook. Esta biblioteca tiene un montón de cosas increíbles. La biblioteca hace honor a su nombre. Es realmente rápida. Hoy sólo vamos a utilizar sus capacidades de predicción del idioma.
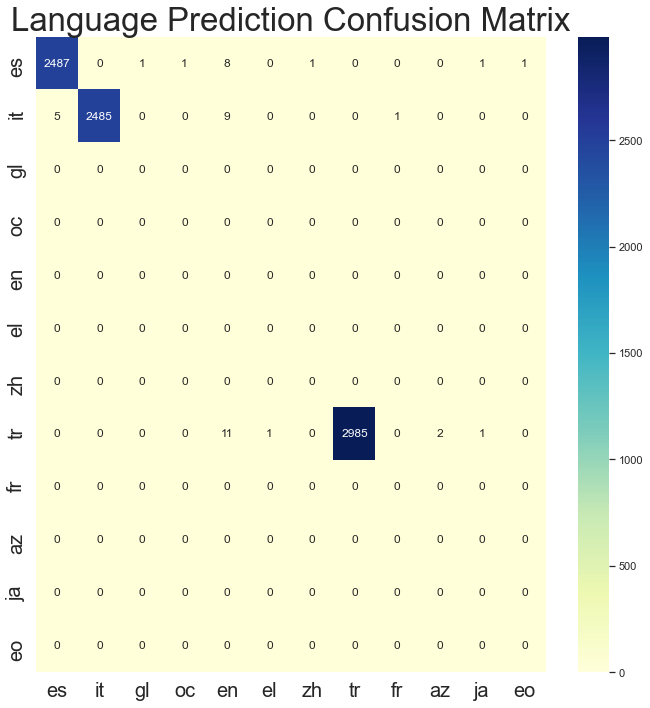
Así de sencillo es identificar qué idioma es una cadena arbitraria. Lo ejecuté sobre el conjunto de validación para tener una idea de lo bien que funcionaba el modelo. Francamente, me sorprendió su rendimiento inicial. De los 8.000 ejemplos, Fasttext sólo clasificó mal 43. Además, sólo tardó 300 ms en ejecutarse en mi MacbookPro. En ambos casos, eso es una barbaridad 🍌. Si te fijas, verás que en algunos de los errores de clasificación del español predijo el gallego o el occitano. Estas son lenguas que se hablan en España y alrededores y que tienen raíces españolas. Así que los errores de predicción en algunos casos no son tan graves como podríamos pensar.
🤗 Transformers 🤗
Ahora que podemos predecir qué idioma es un texto determinado, vamos a ver cómo traducirlo. La transformadores biblioteca de de HuggingFace nunca deja de sorprenderme. Recientemente han añadido más de milmodelos detraducción a su zoo de modelos y cada uno de ellos puede utilizarse para realizar una traducción de textos arbitrarios en unas cinco líneas de código. Estoy robando esto casi directamente de la documentación.
lang = "fr"
target_lang = "enmodel_name = f'Helsinki-NLP/opus-mt-{lang}-{target_lang}'
# Download the model and the tokenizer
model = MarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Tokenize the text
batch = tokenizer([text], return_tensors="pt", padding=True)
# Make sure that the tokenized text does not exceed the maximum
# allowed size of 512
batch["input_ids"] = batch["input_ids"][:, :512]
batch["attention_mask"] = batch["attention_mask"][:, :512]
# Perform the translation and decode the output
translation = model.generate(**batch)
tokenizer.batch_decode(translation, skip_special_tokens=True)
Básicamente, para cualquier par de códigos de idioma puedes descargar un modelo con el nombre Helsinki-NLP/optus-mt-{lang}-{target_lang} donde lang es el código del idioma de origen y target_lang es el código del idioma de destino al que queremos traducir. Si quieres traducir coreano a alemán, descarga el modelo Helsinki-NLP/optus-mt-ko-de. Es así de sencillo 🤯!
Hago una ligera modificación a partir de la documentación, en la que acoto los input_ids y los attention_mask para que sólo tengan 512 tokens. Esto es conveniente porque la mayoría de estos modelos de transformadores sólo pueden manejar entradas de hasta 512 tokens. Esto evita que se produzcan errores en los textos más largos. Sin embargo, causará problemas si intentas traducir textos muy largos, así que ten en cuenta esta modificación si utilizas este código.
Pipelines de SciKit-Learn
Con el modelo descargado vamos a facilitar la incorporación de esto en un pipeline de sklearn. Si has leído alguno de mis posts anteriores probablemente sepas que me encantan los Pipelines de SciKit. Son una buena herramienta para componer la featurización y el entrenamiento del modelo. Así que con eso en mente vamos a crear un simple transformador que tome cualquier dato textual, prediga su lenguaje y lo traduzca. Nuestro objetivo es ser capaces de construir un modelo que sea agnóstico en cuanto al idioma al ejecutarlo:
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline
classifier = svm.LinearSVC(C=1.0, class_weight="balanced")
model = Pipeline([
('translate', EnglishTransformer()),
('tfidf', TfidfVectorizer()),
("classifier", classifier)
])
Este proceso traducirá cada punto de datos de cualquier texto al inglés, luego creará características TF-IDF y después entrenará un clasificador. Esta solución mantiene nuestra featurización en línea con nuestro modelo y facilita el despliegue. También ayuda a evitar que las características se desincronicen con el modelo al realizar la featurización, el entrenamiento y la predicción en una sola línea.
Ahora que sabemos para qué estamos trabajando, ¡construyamos este EnglishTransformer! La mayor parte de este código ya lo habrás visto arriba sólo lo estamos cosiendo. 😄
from typing import List, Optional
from sklearn.base import BaseEstimator, TransformerMixin
import fasttext
from transformers import MarianTokenizer, MarianMTModel
import os
class EnglishTransformer(BaseEstimator, TransformerMixin):
def __init__(self,
fasttext_model_path: str="/tmp/lid.176.bin",
allowed_langs: Optional[List[str]]=None,
target_lang: str="en"):
# If the language model doesn't exist download it
if not os.path.isfile(fasttext_model_path):
url = 'https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin'
r = requests.get(url, allow_redirects=True)
open('/tmp/lid.176.bin', 'wb').write(r.content)
self.fasttext_model_path = fasttext_model_path
self.lang_model = fasttext.load_model(fasttext_model_path)
self.allowed_langs = allowed_langs
self.target_lang = target_lang
self.romance_langs = {"it", "es", "fr", "pt", "oc", "ca", "rm", "wa",
"lld", "fur", "lij", "lmo", "gl", "lad", "an", "mwl"}
if allowed_langs is None:
self.allowed_langs = self.romance_langs.union({self.target_lang, "tr", "ar", "de", "ru"})
else:
self.allowed_langs = allowed_langs
def get_language(self, texts: List[str]) -> List[str]:
# Predict the language code for each text in texts
langs, _ = self.lang_model.predict([x.replace("\n", " ") for x in texts])
# Extract the two character language code from the predictions.
return [x[0].split("__")[-1] for x in langs]
def transform(self, texts: str) -> List[str]:
# Get the language codes for each text in texts
langs = self.get_language(texts)
translations = []
for text, lang in zip(texts, langs):
# If the language is our target just add it as is without doing any prediciton.
if lang == self.target_lang:
translations.append(text)
else:
# Use the romance model if it is a romance language to avoid
# downloading a model for every language
if lang in self.romance_langs and self.target_lang == "en":
lang = "ROMANCE"
translation_model_name = f'Helsinki-NLP/opus-mt-{lang}-{self.target_lang}'
# Download the model and tokenizer
model = MarianMTModel.from_pretrained(translation_model_name)
tokenizer = MarianTokenizer.from_pretrained(translation_model_name)
# Translate the text
inputs = tokenizer([text], return_tensors="pt", padding=True)
gen = model.generate(**inputs)
translations.append(tokenizer.batch_decode(gen, skip_special_tokens=True)[0])
return translations
- Líneas 15-18 – Asegúrate de que el modelo fasttext está descargado y listo para usar. Si no lo está, lo descarga en la carpeta temporal /tmp/lid.176.bin.
- Línea 24 – Establece los códigos de idioma que son traducibles con el modeloROMANCE de Helsinki. Ese modelo maneja un montón de idiomas realmente bien y nos ahorrará un montón de espacio en disco porque no tenemos que descargar un modelo separado para cada uno de esos idiomas.
- Líneas 27-30 – Definir qué idiomas vamos a traducir. Queremos crear una lista de idiomas permitidos porque cada uno de estos modelos ocupa unos 300MB, así que si descargáramos cien modelos diferentes ¡terminaríamos con 30GB de modelos! Esto limita el conjunto de idiomas para que no nos quedemos sin espacio en el disco. Puedes añadir códigos ISO-639-1 a esta lista si quieres traducirlos.
- Líneas 32-38 – Definir una función para realizar la predicción del lenguaje fasttext como hemos comentado anteriormente. Notará que también filtramos el carácter \n. Esto se debe a que Fasttext asume automáticamente que se trata de un punto de datos diferente y arrojará un error si está presente.
- Línea 41- Define la transformación y es donde ocurre la magia. Esta función convierte una lista de cadenas en cualquier idioma en una lista de cadenas en inglés.
- Líneas 48-50 – Comprueba si la cadena actual es de nuestro idioma de destino. Si lo es la añadimos a nuestras traducciones tal cual porque ya es el idioma correcto.
- Líneas 54-55 – Comprueba si el idioma predicho puede ser manejado por el modelo Romance. Esto nos ayuda a evitar la descarga de un montón de modelos lingüísticos adicionales.
- Líneas 56-65 – Deben parecer familiares, son sólo el código de traducción de la documentación de la cara abrazada. Esta sección descarga el modelo correcto y luego realiza la traducción del texto de entrada.
Eso es todo. Super sencillo y puede manejar cualquier cosa. Algo a tener en cuenta es que este código fue escrito para ser lo más legible posible y es MUY lento. Al final de este post, incluyo una versión mucho más rápida que predice por lotes diferentes idiomas en lugar de descargar un modelo para cada punto de datos.
🤑Resultados 🤑
Ahora podemos entrenar y probar nuestro modelo utilizando:
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipelineclassifier = svm.LinearSVC(C=1.0, class_weight="balanced")
model = Pipeline([
('translate', EnglishTransformer()),
('tfidf', TfidfVectorizer()),
("classifier", classifier)
])
model.fit(train_df["comment_text"].tolist(), train_df["toxic"])
preds = model.predict(val_df["comment_text"])
El entrenamiento de un modelo TF-IDF simple en el conjunto de entrenamiento en inglés y la prueba en el conjunto de validación nos da una puntuación F1 para los comentarios tóxicos de 0,15. Eso es terrible. Al predecir cada clase como tóxica se obtiene una F1 de 0,26. Utilizando nuestro nuevo sistema de traducción para preprocesar toda la información y traducirla al inglés, nuestra F1 es de 0,51. Es una mejora de casi 4 veces.
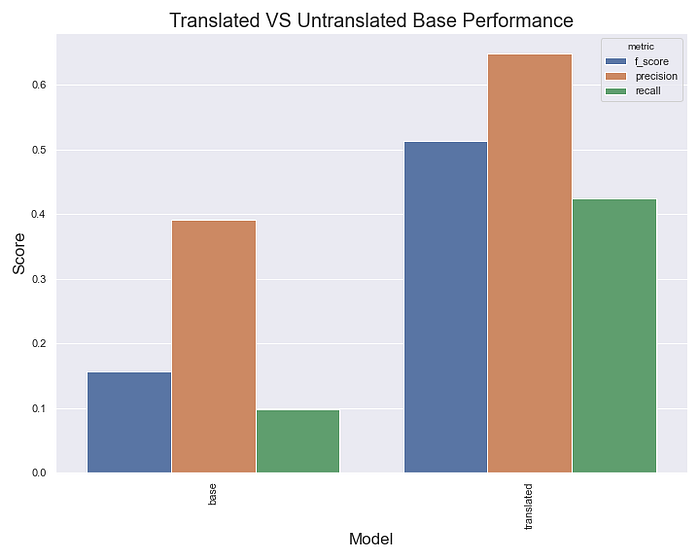
Comparación de resultados entre modelos traducidos y no traducidos
Ten en cuenta que el objetivo aquí era la simple traducción y no necesariamente el rendimiento de SOTA en esta tarea. Si realmente quieres entrenar un modelo de clasificación de comentarios tóxicos que obtenga un buen rendimiento para afinar un modelo de transformación profunda como BERT.
Si te ha gustado esta entrada, echa un vistazo a otra de mis entradas sobre el trabajo con texto y SciKit-Learn.
Gracias por leer! : )
Un Transformer más rápido
Como se prometió, aquí está el código para una versión más rápida del Transformer de Inglés. Aquí ordenamos el corpus por idioma predicho y sólo cargamos un modelo una vez para cada idioma. Se podría hacer aún más rápido mediante el procesamiento por lotes de entrada utilizando el transformador en la parte superior de este.
from typing import List, Optional, Set
from sklearn.base import BaseEstimator, TransformerMixin
import fasttext
from transformers import MarianTokenizer, MarianMTModel
import os
import requests
class LanguageTransformerFast(BaseEstimator, TransformerMixin):
def __init__(
self,
fasttext_model_path: str = "/tmp/lid.176.bin",
allowed_langs: Optional[Set[str]] = None,
target_lang: str = "en",
):
self.fasttext_model_path = fasttext_model_path
self.allowed_langs = allowed_langs
self.target_lang = target_lang
self.romance_langs = {
"it",
"es",
"fr",
"pt",
"oc",
"ca",
"rm",
"wa",
"lld",
"fur",
"lij",
"lmo",
"gl",
"lad",
"an",
"mwl",
}
if allowed_langs is None:
self.allowed_langs = self.romance_langs.union(
{self.target_lang, "tr", "ar", "de"}
)
else:
self.allowed_langs = allowed_langs
def get_language(self, texts: List[str]) -> List[str]:
# If the model doesn't exist download it
if not os.path.isfile(self.fasttext_model_path):
url = (
"https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin"
)
r = requests.get(url, allow_redirects=True)
open("/tmp/lid.176.bin", "wb").write(r.content)
lang_model = fasttext.load_model(self.fasttext_model_path)
# Predict the language code for each text in texts
langs, _ = lang_model.predict([x.replace("\n", " ") for x in texts])
# Extract the two character language code from the predictions.
return [x[0].split("__")[-1] for x in langs]
def fit(self, X, y):
return self
def transform(self, texts: str) -> List[str]:
# Get the language codes for each text in texts
langs = self.get_language(texts)
# Zip the texts, languages, and their indecies
# sort on the language so that all languages appear together
text_lang_pairs = sorted(
zip(texts, langs, range(len(langs))), key=lambda x: x[1]
)
model = None
translations = []
prev_lang = text_lang_pairs[0]
for text, lang, idx in text_lang_pairs:
if lang == self.target_lang or lang not in self.allowed_langs:
translations.append((idx, text))
else:
# Use the romance model if it is a romance language to avoid
# downloading a model for every language
if lang in self.romance_langs and self.target_lang == "en":
lang = "ROMANCE"
if model is None or lang != prev_lang:
translation_model_name = (
f"Helsinki-NLP/opus-mt-{lang}-{self.target_lang}"
)
# Download the model and tokenizer
model = MarianMTModel.from_pretrained(translation_model_name)
tokenizer = MarianTokenizer.from_pretrained(translation_model_name)
# Tokenize the text
batch = tokenizer([text], return_tensors="pt", padding=True)
# Make sure that the tokenized text does not exceed the maximum
# allowed size of 512
batch["input_ids"] = batch["input_ids"][:, :512]
batch["attention_mask"] = batch["attention_mask"][:, :512]
gen = model.generate(**batch)
translations.append(
(idx, tokenizer.batch_decode(gen, skip_special_tokens=True)[0])
)
prev_lang = lang
# Reorganize the translations to match the original ordering
return [x[1] for x in sorted(translations, key=lambda x: x[0])]