Internacionalización (i18n) y localización (L10n) de software
Traducción de Inglés a Español de un interesantísimo artículo de Dawei Ma, desarrollador de Xian, que nos explica detalladamente cómo implementar un proyecto de traducción de software, incluyendo tanto internacionalización (varios entornos lingüísticos) como localización (entorno lingüístico regional específico)
 1 marzo, 2022 Traducción e internacionalización de software
1 marzo, 2022 Traducción e internacionalización de software Guía completa sobre internacionalización (i18n) y localización (i10n) de software, dos conceptos que conforman todo proyecto de traducción de software. Diferencias entre ambos conceptos, y descripción detalla da de procesos: ¿Cómo internacionalizar un software para poder traducirlo a diferentes idiomas y localizarlo para diferentes paises? Un texto original escrito por Dawei Ma.
***
Un producto exitoso necesita hacerse global a través de un proceso de muchas etapas, pero desde la perspectiva del desarrollo de software hay 2 procesos esenciales: la internacionalización y la localización.
Disclaimer: Esta es una traducción gratuita realizada por Jose. Si necesitas servicio de traducciones a nivel profesional para cualquier software o App, contacta con uno de nuestros expertos en traducción y localización de software. Agencia de traducción en Madrid Ibidem Group. Agencia de traducción en Barcelona Ibidem Group.
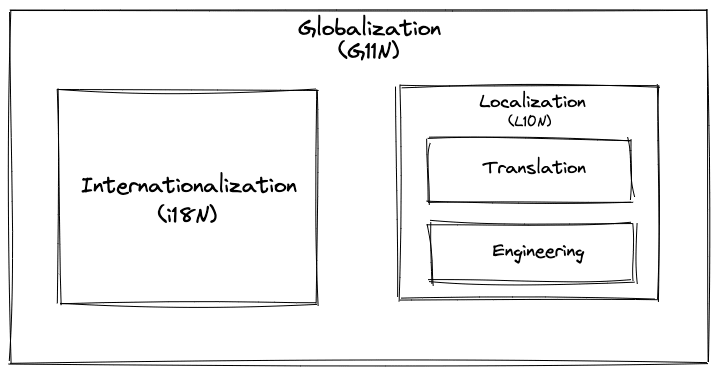
Un entorno lingüístico es el uso de una lengua o variante lingüística específica dentro de un país o región geográfica, que determina el formato y el análisis sintáctico de las fechas, horas, números y monedas, así como las distintas unidades de medida y los nombres traducidos de las zonas horarias, idiomas, países y regiones. La internacionalización permite a un programa informático manejar varios entornos lingüísticos, mientras que la localización permite a un programa informático soportar un entorno lingüístico regional específico. Esto significa que el proceso de globalización consiste en hacer primero que el software se internacionalice, y luego hacer la implementación de la localización para que pueda soportar un entorno lingüístico específico en una región específica.
A menudo se abrevian como i18n (18 significa que hay 18 letras entre la i y la n en la palabra «internacionalización») y L10n, respectivamente, debido a la longitud de sus palabras sueltas, utilizando una L mayúscula para distinguir la i en i18n y para que sea fácil distinguir la l minúscula del 1.(Wikipedia)
INDICE
Internacionalización (i18N)
Problemas que hay que resolver para la internacionalización
- La posibilidad de mostrar el texto en la lengua materna del usuario.
- Posibilidad de introducir texto en la lengua materna del usuario.
- Capacidad de procesar texto en la lengua materna del usuario en una codificación específica.
Codificación del texto
El conjunto de caracteres Unicode puede mostrar casi todos los caracteres conocidos por el hombre en puntos de código que van de 0 a 10FFFF (hexadecimal). Requiere al menos 21 bits para su almacenamiento. El sistema de codificación de texto UTF-8 adapta los puntos de código Unicode a un flujo de datos razonable de 8 bits y es compatible con el sistema de procesamiento de datos ASCII.UTF son las siglas de Unicode Transformation Format.
Desde 2009, UTF-8 ha sido la forma de codificación dominante en la World Wide Web. En noviembre de 2019, UTF-8 se utiliza en el 94,3% de todas las páginas web (algunas de las cuales son solo ASCII, ya que es un subconjunto de UTF-8), y en el 96% de las 1000 primeras páginas. Por lo tanto, se recomienda la codificación UTF-8 para la internacionalización.
Este artículo La internacionalización de los productos informáticos nunca es suficiente para «soportar el inglés» menciona que algunos textos codificados en GBK tienen muchas El texto que «parece igual» es en realidad ligeramente diferente. Sin embargo, para ahorrar espacio en Unicode, se les asigna el mismo punto de código.

¿Cómo podemos distinguir estos caracteres idénticos con el mismo código (mostrando un carácter en un glifo diferente, es decir, el mismo carácter)? Para ello se necesita la ayuda de la configuración regional.
Cuando se calcula el número de caracteres chinos, se suele hacer por forma de carácter, es decir, simplificado, tradicional, variante, nuevo, antiguo, etc., de un carácter que representa el mismo significado fonético. Esta forma de contar es, de hecho, contar variantes. Por ello, durante mucho tiempo se ha considerado erróneamente que el número de glifos incluidos en los grandes diccionarios es el tamaño del sistema de caracteres chinos.(Wikipedia)
Locale
Una configuración regional es el entorno lingüístico del software en tiempo de ejecución, que incluye Idioma, Territorio y Conjunto de códigos. Una configuración regional se escribe con el siguiente formato Idioma[_Territorio[. UTF8. En Linux, una configuración regional consta de las siguientes partes.
- LC_COLLATE: Controla la ordenación de los caracteres.
- LC_CTYPE: controla la función de manejo de caracteres en el manejo de mayúsculas y minúsculas o la determinación de si es un carácter.
- LC_MESSAGES: formato de los mensajes de aviso.
- LC_MONETARIO: formato de la moneda.
- LC_NUMERIC: el formato del número.
- LC_TIME: el formato de la hora.
Si su configuración regional es en_US.UTF8, debe cambiarla a zh_CN.UTF8 para que el chino se muestre correctamente. Todas las configuraciones regionales compatibles se almacenan en el directorio /usr/share/locale del sistema operativo macOS.

Códigos de idiomas y países
La misma lengua puede tener algunas diferencias sutiles en distintos países y regiones, por ejemplo, hay algunas diferencias entre el inglés americano y el inglés británico. El mismo país también puede tener varios idiomas, por ejemplo, China tiene idiomas simplificados y tradicionales. En la introducción a locale anterior vimos el uso de language_region para expresar el idioma exacto de un país.
Para los países e idiomas, la ISO ha desarrollado los correspondientes códigos estándar ISO 3166-1 e ISO 639-1.
El navegador utiliza el código de idioma para enviar el nombre del idioma aceptado por el navegador en la cabecera HTTP Accept-Language. Por ejemplo: it, de-at, es, pt-br.
Gettext
GNU gettext es la biblioteca de internacionalización y localización de GNU (i18n), que se utiliza a menudo para escribir programas de multilingüismo (M17N). Muchos lenguajes de programación como C, C++, Python, PHP, Rust, Elixir, etc. soportan el uso de gettext desde el propio lenguaje.
El siguiente es el flujo de cómo Java llama a gettext para completar la internacionalización.

- xgettext escanea el código fuente para extraer las cadenas de entrada para las funciones i18n tr(), trc() y trn() y crea un archivo pot que contiene todas las cadenas del idioma fuente. El objeto con el que el traductor necesita trabajar es el archivo .po, que es generado por el programa msginit a partir del archivo de plantilla .pot.
- msgmerge fusiona las cadenas en un archivo po que contiene las traducciones para una única localización.
- msgfmt se utiliza para generar archivos de clase Java que heredan de la clase Java ResourceBundle.
El siguiente diagrama muestra el flujo de la internacionalización en PHP usando gettext.

Elixir implementa la estructura de directorios de i18n utilizando gettext.
priv/gettext
└─ es_US
| └─ LC_MESSAGES
| ├─ default.po
| └─ errores.po
└─ it
└─ LC_MESSAGES
├─ default.po
└─ errores.po
Proceso de internacionalización
El proceso de usar gettext es un proceso típico para hacer que una aplicación soporte la internacionalización i18n.
- Configurar el marco i18n. El marco i18n obtiene automáticamente los archivos de idioma relevantes por el identificador de idioma del sistema o del navegador (en el caso de las aplicaciones web). Por ejemplo, gettext utiliza un archivo con sufijo .mo, mientras que Javascript suele ser un archivo .json y Java un archivo .properties.
- extraer el texto del idioma fuente codificado. Llame a la función i18n en el lugar codificado. Para esta parte se puede extraer manualmente, o automáticamente a través de un programa o plugin (por ejemplo, el marco de internacionalización i18next para Javascript tiene i18next-scanner).
- finalmente, implementar la localización. Traducir (manualmente o mediante traducción automática, también hay plataformas de traducción relevantes que pueden integrarse) estos archivos extraídos en el idioma del país al que se va a dar soporte.
Localización (L10N)
Proceso de localización
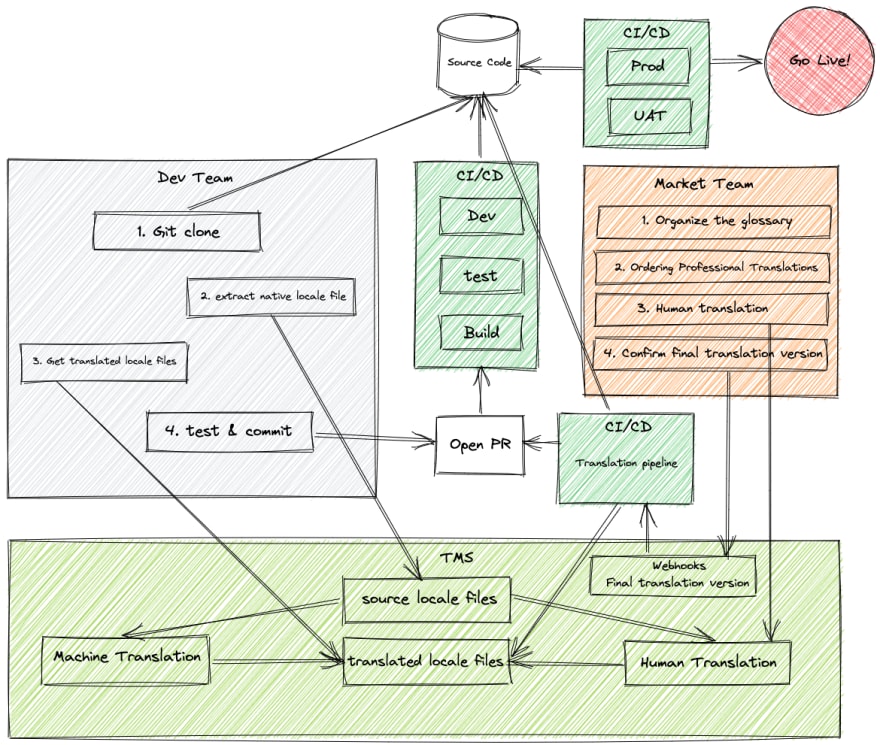
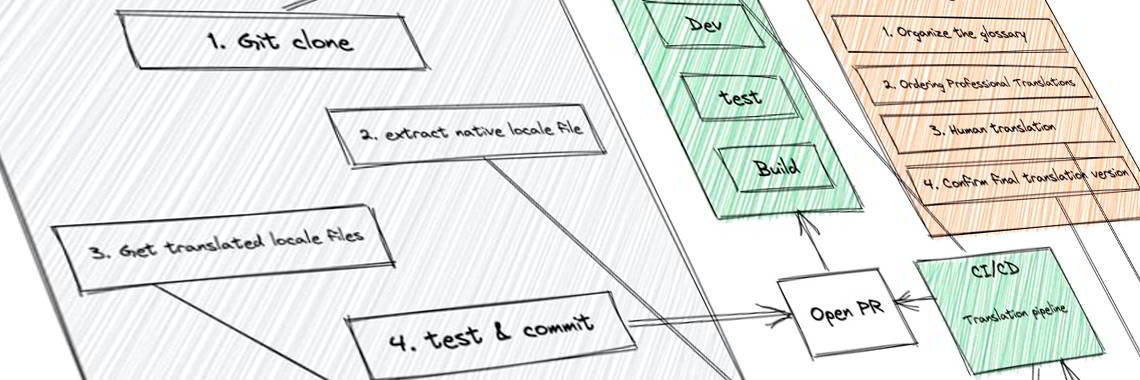
En la figura anterior se muestra un diagrama de flujo de localización típico. Entre las partes implicadas se encuentran.
- Equipo de desarrollo: Los desarrolladores internacionalizan el sistema y despliegan la versión traducida por la máquina de la versión multilingüe en el entorno de integración para que los probadores la prueben, y pueden construir una tubería de integración de traducción automática.
- Equipo de mercado: Confirmar el mercado y los idiomas admitidos del producto, organizar el glosario de términos relacionados con el producto y adquirir servicios de traducción profesionales para determinar la versión final traducida en varios idiomas. En el caso de las grandes empresas, puede haber un equipo de globalización dedicado a realizar este trabajo.
- Plataforma de gestión de la traducción (TMS): completa la gestión de los idiomas de traducción, generalmente con interfaces API específicas o kits de desarrollo SDK que pueden integrarse en entornos CI/CD y pueden automatizar la carga y descarga de archivos de idiomas de origen y de traducción. También dispone de una interfaz de gestión para que los traductores puedan modificar y determinar la versión final de la traducción. Puede ofrecer múltiples servicios de traducción automática, así como proporcionar traducción humana para su compra o traducción humana completa de forma colaborativa de código abierto.
Desarrollar una estrategia de localización
Región y lengua
Esta pieza comienza con estas consideraciones básicas de los antecedentes.
- Implicaciones empresariales de la región
- Región por defecto del usuario
- Idioma por defecto de la configuración regional
- Si las diferentes regiones utilizan el mismo sistema
- Si se admite que los usuarios cambien de idioma
- Si el usuario puede pertenecer a varios locales
- Si existe una relación unívoca entre localidad y país
- Asignación entre la localidad y el idioma
- ¿Existe un vínculo entre la configuración regional y el idioma (el usuario puede ver todos los idiomas admitidos por todas las configuraciones regionales)?
- Si es necesario guardar el cambio de idioma en la información personal del usuario
- Si el idioma por defecto del usuario debe ser establecido por el identificador de idioma del entorno del usuario (SO o navegador)
- Si el servicio se despliega en varias geografías y si los datos están aislados en varias geografías
Añadir una nueva región/idioma/servicio
- Si el sistema puede soportar el proceso de adición de nuevas regiones y
- Si el sistema puede soportar el proceso de añadir nuevas lenguas y el proceso de añadir nuevas lenguas
- El proceso de localización al añadir subservicios al sistema
Localización incremental
- Proceso de localización cuando aparecen nuevas páginas o componentes cuando se implementa la localización
Gestión de la traducción
- Si necesita una plataforma de gestión de la traducción (TMS)
- Selección de la plataforma de gestión de la traducción
- Integración de la plataforma de gestión de la traducción
- Si se suscribe a los servicios de traducción profesional
- Desarrollo de procesos de colaboración con los equipos de traducción
Aplicación localizada
- Si cada servicio del sistema está localizado por su propio equipo de desarrollo
- Si hay un equipo de localización dedicado a la localización
- El modo de colaboración entre el equipo de localización y cada equipo de desarrollo de servicios
- Si la localización se hace por código Open PR
- Cómo hace cada equipo de desarrollo de servicios la localización incremental
- Sincronización de conocimientos sobre localización entre equipos
- Desarrollo de normas técnicas para la localización y promoción dentro de la organización
- Uso de bibliotecas estándar del sector (por ejemplo, Unicode Common Locale Data Repository CLDR) para los formatos específicos de cada idioma para fechas, horas, husos horarios, números y monedas
- El identificador de la configuración regional está en formato language_region, por ejemplo, en_US para el idioma inglés de los Estados Unidos.
Aplicación multilingüe localizada
- Distinguir el multilingüismo por subdominios (gTLDS) o ccTLDs (por ejemplo, ccTLDs). Por ejemplo: https://en.wikipedia.org/
- Distinguir el multilingüismo por las rutas de URL. Por ejemplo: https://localizejs.com/de/
- Multilingüe por parámetros de consulta de la URL (no es amigable para el SEO). Por ejemplo, https://locize.com/?lng=de
- Multilenguaje mediante la configuración del idioma del usuario. Por ejemplo, https://myaccount.google.com/language
- Multilingüe por almacenamiento local del navegador. Por ejemplo, https://www.instagram.com/
Los retos de la localización

Los retos de la localización son, sobre todo, cuestiones derivadas de las diferencias lingüísticas, culturales, de hábitos de escritura y de leyes en las distintas zonas geográficas, en las siguientes categorías.
- Codificación del texto: Para los textos de la mayoría de las lenguas de Europa Occidental, basta con la codificación de caracteres ASCII. Sin embargo, los idiomas que utilizan alfabetos no latinos (por ejemplo, el ruso, el chino, el hindi y el coreano) requieren una codificación de caracteres mayor, como Unicode.
- Singular y plural: Las distintas lenguas tienen diferentes formas de singular y plural. El plural se utiliza para representar un número que «no es uno». Las formas de singular y plural varían de una lengua a otra, siendo la más común el plural para representar números de dos o más. En algunas lenguas, también se utiliza para representar fracciones, ceros, números negativos o doses.
- Traducción de imágenes: Es necesario traducir las imágenes con texto.
- Datos dinámicos (datos de la API): Los datos que se pasan del back-end al front-end y que se muestran en la interfaz deben ser localizados. Pero es un reto distinguir la fuente de estos datos, por ejemplo, aunque los datos provengan del back-end, pueden venir de una base de datos, pueden venir de un archivo, pueden venir de otros servicios internos, o pueden venir de un servicio dependiente de terceros.
- Iconos: Algunos iconos que son muy reconocidos en una región pueden parecer completamente irreconocibles para los usuarios de otras regiones o ser otra cosa.
- Nombre/dirección: El orden del apellido y del nombre, y el orden en que se escriben las direcciones. Por ejemplo, en chino, el apellido va primero y luego el nombre.
- El género: Algunas lenguas, como el francés, hacen mucho hincapié en el género.
- Teléfono: El formato de las llamadas telefónicas varía de un país a otro.
- Voz: Las voces o señales inapropiadas pueden resultar ofensivas, y algunos países son sensibles al género de la voz.
- Color: Los colores y las tonalidades se asocian a las regiones geográficas o a los mercados, por ejemplo, el rojo en Estados Unidos indica un descenso y en el A-share una subida.
- Unidades de medida
- Moneda: El formato de la moneda debe tener en cuenta el símbolo de la moneda, la posición del símbolo de la moneda y la posición del signo menos. La mayoría de las monedas utilizan el mismo separador decimal y el mismo separador de miles que los números de la configuración regional o de área. Sin embargo, en algunos lugares no es así, por ejemplo en Suiza, el separador decimal del franco suizo es un punto.
- Fecha y hora: La internacionalización de la fecha/hora implica no sólo la localización geográfica (por ejemplo, la representación localizada del calendario, como el día de la semana, el mes, etc.), sino también la zona horaria (TimeZone, para los desfases UTC/GMT). Las zonas horarias no sólo están definidas geográficamente, sino también políticamente. Por ejemplo, China abarca geográficamente 5 zonas horarias, pero sólo utiliza una zona horaria unificada. Muchos otros países tienen «horario de verano» y la diferencia entre la hora de Berlín y la de Pekín está sujeta a cambios. A veces es de 7 horas (horario de invierno), otras de 6 (horario de verano).
- Los números: También hay diferencias en la forma de representar los números en los distintos países y regiones. Los factores que afectan a la representación de los números son la representación de los caracteres numéricos, la representación de los símbolos numéricos, el tipo de números, etc.
- Unidades de peso/longitud/físicas: Debido a las diferencias en las unidades, es necesario convertir múltiples versiones geográficas del mismo conjunto de datos.
- Unidades de medida relacionadas con el negocio: Por ejemplo, los distintos países tienen reglas de facturación diferentes para sus productos. Esto requiere el apoyo del personal empresarial para averiguar la posición correspondiente y dar las reglas de conversión.
- La longitud de las frases: El alemán suele ser más largo que el inglés, y el árabe requiere más espacio vertical.
- Dirección de la escritura: En muchos idiomas es de izquierda a derecha, pero en hebreo y árabe es de derecha a izquierda y en algunas lenguas asiáticas es vertical.
- Puntuación: por ejemplo, comillas («») en inglés, comillas bajas (,,») en alemán y comillas (<<>>) en francés.
- Saltos de línea/saltos: Las reglas del juego de caracteres asiático CJK (chino, japonés y coreano) son completamente diferentes de las de los idiomas occidentales. Por ejemplo, a diferencia de la mayoría de las lenguas escritas occidentales, el chino, el japonés, el coreano y el tailandés no utilizan necesariamente espacios para separar una palabra de la siguiente. El tailandés ni siquiera utiliza signos de puntuación.
- Conversión de mayúsculas y minúsculas: El inglés tiene conversión de mayúsculas y minúsculas, mientras que el chino no tiene distinción de mayúsculas y minúsculas.
- Relacionados con la legislación: por ejemplo, el GDPR que utiliza datos personales de ciudadanos de la UE.
- Relacionados con la política: Por ejemplo, la localización implica la visualización de banderas y mapas, que pueden causar fácilmente accidentes importantes si no se manejan adecuadamente.
- Métodos de clasificación: Por ejemplo, el inglés se ordena alfabéticamente, mientras que el chino puede ordenarse en pinyin.
¿Necesita tener en cuenta el SEO?
Si está localizando un sitio web para toC, debe tener en cuenta algunas cosas relacionadas con la optimización de los motores de búsqueda (SEO), como por ejemplo este Cómo enfocar una estrategia internacional menciona algunos puntos clave.
- Si ofrece su sitio en varios idiomas, utilice un solo idioma para el contenido y la navegación en cada página, y evite las traducciones paralelas.
- Mantenga el contenido en cada idioma en una URL separada y marque el idioma en la URL. Por ejemplo, la URL www.mysite.com/de/ indicaría al usuario que la página está en alemán.
- Muestra el idioma que quieres localizar a Google a través de la metaetiqueta hreflang. Por ejemplo, < link rel=»alternate» href=»http://example.com» hreflang=»en-us» />.
- No traduzca sólo el texto de la plantilla, sino también el contenido de la misma.
- no utilizar exclusivamente la traducción automática, que puede afectar a la experiencia del usuario
- no utilice cookies o técnicas de scripting para cambiar de idioma, los rastreadores de Google no pueden indexar este contenido correctamente.
Localización del diseño del producto
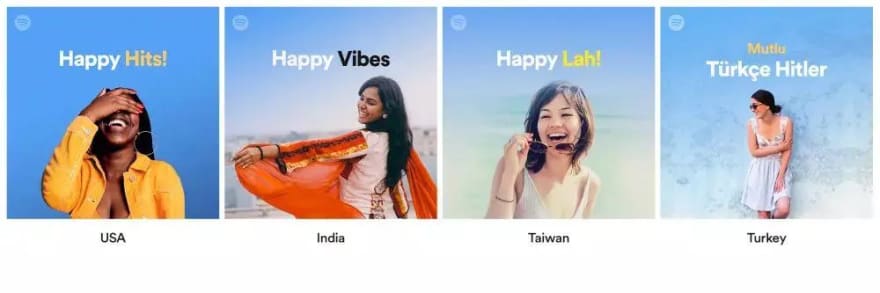
Utilizar un diseño más localizado para el mismo contenido en distintas geografías puede dar mejores resultados, como se menciona en el artículo Internacionalización y localización del diseño de productos sobre la diferente presentación de las carátulas de las canciones de Spotify en distintos países.
Localización en los microservicios
El proceso de localización de una sola aplicación es relativamente sencillo desde el punto de vista arquitectónico. Sin embargo, hoy en día muchas aplicaciones son arquitecturas de microservicios con múltiples equipos que colaboran en el modelo de desarrollo. Si los equipos individuales son responsables de la localización de sus respectivos servicios, debe haber un comité de localización unificado para desarrollar normas técnicas de localización.
- La identificación de los marcadores lingüísticos.
- El diseño de la conmutación de idiomas en las soluciones frontales y secundarias.
- El diseño del proceso de automatización de la traducción, etc.
O bien, hay un equipo de localización dedicado a implementar la localización, y este equipo se encargará de resolver los problemas anteriores. El proyecto en el que participo entra en esta última categoría. Nuestro equipo completó la localización de casi una docena de subsistemas de microservicios para todo el gran sistema, y estas docenas de sistemas fueron manejados por varios grupos grandes de múltiples equipos, por lo que el proceso de colaboración de tales requisitos interfuncionales (CFR) a través de múltiples equipos es una tarea compleja.
Desarrollo de normas técnicas o empresariales localizadas
Antes de aplicar la localización, es importante identificar las normas técnicas u operativas pertinentes, algunas de las cuales son.
- Estándares de implementación de la internacionalización para diferentes pilas tecnológicas en los extremos delantero y trasero. Dado que puede haber múltiples pilas tecnológicas en los microservicios, cada una con su propia implementación de internacionalización, el desarrollo de estándares de implementación para diferentes pilas tecnológicas puede ayudar a utilizar la misma implementación en todos los servicios.
- La determinación de los marcadores de localización.
- La posibilidad de almacenar texto relacionado con el idioma en la extracción de texto estático del front-end o del back-end a archivos nombrados por identificadores de idioma, por ejemplo, en.json para el texto estático en inglés, y en_US.json para el texto relacionado con el inglés estadounidense (por ejemplo, unidades de medida, fechas, números, moneda, etc.).
- El formato language_region se utiliza de manera uniforme en las llamadas a servicios remotos (llamadas del front-end al back-end o del back-end a otros servicios internos o externos), por ejemplo, en_US significa obtener la versión localizada del idioma inglés para la región de Estados Unidos.
- Los formatos específicos del idioma para fechas, horas, husos horarios, números y monedas utilizan bibliotecas estándar del sector. Por ejemplo, utilizando bibliotecas que implementan el estándar CLDR.
- Identificación del tipo de datos dinámicos. Identificar, por ejemplo, qué datos provienen de sistemas internos (bases de datos o archivos); cuáles provienen de sistemas externos; si estos datos dinámicos tienen capacidad de internacionalización; y cómo localizarlos por etapas.
- Localización de documentos. Localización de documentos electrónicos (PDF) o correos electrónicos generados por el sistema de back-office. Si estos documentos se envían a los clientes, considere también la posibilidad de generar los documentos en el idioma que prefiera el cliente.
- Lista de regiones e idiomas soportados. Por ejemplo, si se entra en la página de error cuando aparece un país o idioma no soportado o si se muestra la versión regional o de idioma localizado por defecto.
- La región y el idioma por defecto.
- si la región y la lengua tienen una relación vinculante.
- Si el cambio de idioma debe guardarse en la información personal del usuario.
Entorno de desarrollo y procesos empresariales
De hecho, la parte de la localización que más tiempo consumió a nuestro equipo fue la puesta en marcha del entorno local. Con tantos servicios implicados y ligeras diferencias en la forma de poner en marcha los distintos servicios, e incluso documentos de orientación erróneos, teníamos que ir pisando el acelerador para terminar de configurar el entorno. Al final, nuestra forma de afrontarlo fue contactar con los equipos de desarrollo, y cada vez que hacíamos la prelocalización de un servicio, pedíamos al equipo de desarrollo que nos ayudara a configurar el entorno local.
Otra dificultad era nuestra falta de comprensión del negocio. Dado que cada servicio tiene un gran número de componentes y páginas, incluidos los datos dinámicos de diferentes fuentes de servicios de back-end, era difícil de entender por nosotros mismos. Al final, cuando hicimos la prelocalización de este servicio, conseguimos que los analistas de negocio del equipo de desarrollo nos ayudaran a introducir los procesos de negocio implicados en este servicio.
Tratamiento de textos estáticos
- Clasificación del texto estático en los extremos delantero y trasero para identificar qué sistemas tienen capacidades de internacionalización (las versiones lingüísticas iniciales han tenido archivos de localización extraídos y bibliotecas de internacionalización configuradas).
- Identificar dónde aparecen los formatos de fecha, moneda y número y llamar a las bibliotecas estándar del sector identificadas por las normas técnicas de localización en esos lugares.
- Identificación de los procesos incrementales de traducción de textos estáticos, que deben utilizarse para procesar nuevos textos cuando se añaden después de que el sistema ya ha sido localizado, utilizando procesos de localización.
- Integración automatizada de plataformas de traducción, en las que los equipos de desarrollo utilizan scripts o flujos de CI/CD para cargar y descargar automáticamente archivos en los idiomas original y traducido.
Almacenaje de los ajustes de idioma y región
Algunos sitios internacionalizados tienen el cambio de idioma o región diseñado como hipervínculos que permiten a los usuarios acceder a versiones del sitio en diferentes idiomas y regiones, que no requieren almacenar configuraciones de idioma o región.
Los sitios con configuración de perfiles de usuario suelen ofrecer la posibilidad de establecer el idioma y la región preferidos en la configuración del perfil, de modo que los usuarios puedan sincronizar el último idioma o región establecidos al cambiar de dispositivo.
Si los usuarios de su sitio cambian de dispositivo con poca frecuencia, un simple proceso puede almacenar estas configuraciones en el almacén del navegador. Cuando el usuario cambia de dispositivo, la configuración por defecto se restablece automáticamente. La ventaja de un diseño de este tipo es que es sencillo, y es más fácil adelantar a otras soluciones más adelante. El diseño específico elegido debe combinarse con el negocio específico a elegir.
Localización de los servicios de back-end
La localización de los servicios de back-end implica los siguientes cuatro componentes.
- Texto estático. Se puede leer recorriendo el código para encontrar la cadena correspondiente.
- Bases de datos, cachés o archivos. Los datos iniciales que no satisfacen las necesidades de localización pueden encontrarse recorriendo el script de inicialización de la base de datos, pero en el caso de los datos almacenados dinámicamente, es necesario diseñar las tablas para que también satisfagan el almacenamiento multilingüe. En el caso de algunos archivos de recursos en los que es necesaria la traducción, también es necesario proporcionar versiones multilingües y adaptar el código que utiliza los archivos.
- Llamadas remotas a otros servicios internos (RPC). Los marcadores de localización para las llamadas a servicios internos forman parte de los estándares tecnológicos de localización desarrollados. Por ejemplo, la cabecera HTTP locale = en_US puede utilizarse para solicitar páginas en inglés para Estados Unidos.
- Generar documentos (PDF o correo electrónico). Los documentos generados incluyen la versión final en el idioma del texto estático de la plantilla y la representación de los datos dinámicos. Especialmente cuando estos documentos y correos electrónicos deben ser enviados a los usuarios, deben ser generados en el idioma que coincida con el del usuario.
Si la pila tecnológica del servicio back-end es diferente, el equipo de localización también debe resumir el proceso de internacionalización para las diferentes pilas tecnológicas del servicio back-end y sincronizarlo con otros equipos de desarrollo de la organización.
Localización de servicios y recursos de terceros
Hay casos en los que se llama a servicios externos en la llamada remota del servicio backend. Si llama a servicios externos, necesita confirmar primero si los servicios externos soportan la versión multilingüe, y si lo hacen, puede integrarlos de acuerdo con la documentación de acoplamiento. Si no es así, debe ponerse en contacto con el proveedor del servicio externo para determinar el plan de soporte.
Proceso de liberación
Dado que la implementación de la localización implica la transformación de más de una docena de subservicios, la localización puede ser controlada mediante Feature Toggles para ser activada o desactivada en diferentes entornos. Las pruebas afectadas por la localización (pruebas unitarias, pruebas de integración y pruebas de interfaz de usuario) también deben controlarse mediante Feature Toggles para que el conjunto de pruebas del servicio original se vea mínimamente afectado.
Una vez que se hayan localizado e implementado todos los servicios, se pueden abrir los conmutadores de funciones localizados para todos los servicios para poner en línea la versión final.
Hay dos diseños para elegir en lo que respecta a los conmutadores de funciones localizados.
- Por ejemplo, se puede crear un servicio de configuración de características centralizado, y todos los servicios relacionados con la localización solicitan este servicio para obtener el estado del interruptor de configuración. La ventaja es que las funciones localizadas pueden activarse y desactivarse en tiempo real sin necesidad de volver a conectarse. La desventaja es que no hay flexibilidad para controlar las características localizadas de cada servicio.
- Interruptores de funciones independientes: En contraste con el centralizado, cada servicio establece sus propios Feature Toggles localizados para un desacoplamiento flexible, pero la desventaja es que cada interruptor requiere un nuevo lanzamiento para poner en línea un solo servicio.
Localización en la arquitectura de microfronteras
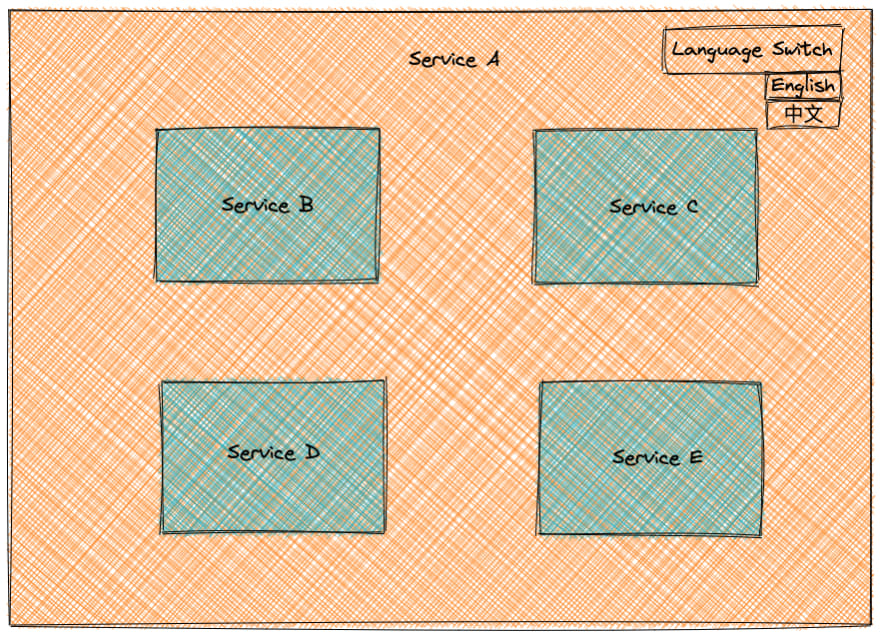
Como la figura anterior muestra un sitio web de arquitectura micro front-end, toda la interfaz del sitio web se compone de cinco páginas de servicio A/B/C/D/E. El botón de cambio de idioma se encuentra en el servicio A. Cuando el usuario cambia del inglés al chino, los demás servicios B/C/D/E tienen que cambiar sus respectivas interfaces a la versión en chino.
Una forma es tener la instancia de la biblioteca de internacionalización (i18n) inicializada por el Servicio A y montada en el objeto ventana del navegador cuando éste carga la página, y los Servicios B/C/D/E utilizan el objeto instancia de la biblioteca de internacionalización inicializado por el Servicio A. Cuando se cambia de idioma, el objeto instancia de internacionalización del Servicio A cambia el idioma de todos los servicios.
Los archivos de localización de cada servicio pueden ser cargados en el navegador de manera uniforme por el Servicio A. La ventaja de este enfoque es que sabemos cuándo se ha cargado el último archivo de idioma, lo que significa que la localización de todos los servicios en toda la página se inicializa y el usuario puede cambiar de idioma normalmente.
Tests de localización
Las pruebas de localización verifican que el contenido de la aplicación o del sitio web cumple con los requisitos lingüísticos, culturales y geográficos de un país o región determinados.
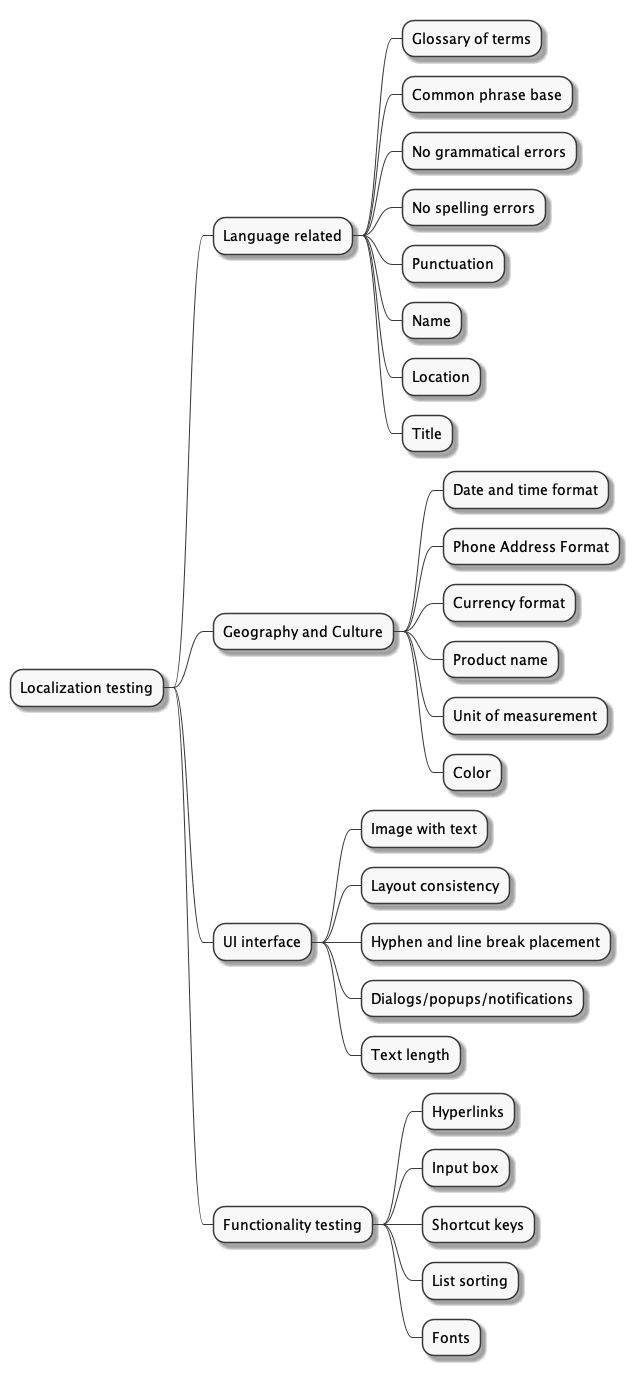
Para más detalles, consulte este artículo Tests de localización: por qué y cómo hacerlas.
Plataforma de localización
Una pieza muy importante de la localización es la selección de una plataforma de gestión de la traducción (TMS) adecuada, que generalmente tiene las siguientes funcionalidades.
- Glosario: Un glosario de términos especializados de la marca o del dominio que puede ayudar a los traductores a traducir con mayor precisión el lenguaje especializado relacionado con un producto o mercado.
- Memoria de traducción (TM): La MT es una base de datos que almacena cadenas de contenido previamente traducido. Las traducciones se reutilizan para contenidos iguales o similares. Esto garantiza la coherencia de las traducciones.
- Editor de contexto (In-Context Editor): Este editor rastrea las páginas del sitio web y permite a los traductores comprender el contexto de toda la página, lo que ayuda a mejorar la calidad de la traducción.
- Traducciones automáticas (Machine Translations): la mayoría de las plataformas TMS están acopladas a algunas plataformas de traducción automática (como Google Translate), que pueden traducir automáticamente el idioma de destino y son adecuadas para los desarrolladores.
- Traducciones humanas: Los servicios profesionales de traducción humana pueden encargarse desde la plataforma TMS. Sin embargo, también hay funciones como Crowdin, que ofrece colaboración de traducción localizada para proyectos de código abierto, y cualquiera puede participar en este proyecto de forma gratuita, y el texto traducido con más votos se utilizará primero.
Principales plataformas de localización.
Con esto concluyen esta introducción a la internacionalización y al proceso básico de traducción y localización de software. La localización es una tarea compleja, y la mayor dificultad es no saber lo suficiente sobre la lengua y la cultura de destino. Pero después de haber leído este artículo, espero que te dé más confianza para llevar a cabo proyectos relacionados con la localización.
Articulos relacionados
Traducción de Inglés a Español de un interesantísimo artículo de Dawei Ma, desarrollador de Xian, que nos explica detalladamente cómo implementar un proyecto de traducción de software, incluyendo tanto internacionalización (varios entornos lingüísticos) como localización...
Traducción de Inglés a Español de un interesantísimo artículo de Dawei Ma, desarrollador de Xian, que nos explica detalladamente cómo implementar un proyecto de traducción de software, incluyendo tanto internacionalización (varios entornos lingüísticos) como localización...

Traducción de un interesante artículo de Dana Woodman explicando cómo añadir traducciones y localización sencilla a una app Svelte. El método se basa en un post de Matthias Stahl, pero Dana Woodman explica cómo hacerlo sin necesidad de crear un repositorio adicional para las...