Todo sobre BERT, el modelo lingüístico más avanzado para NLP a día de hoy.
Breve introducción a BERT el modelo lingüístico más avanzado para Procesamiento de lenguaje (NLP) y Traducción Automática (MT), de la mano de Rani Horev.
 26 agosto, 2021 BERT el modelo lingüístico más avanzado para NPL.
26 agosto, 2021 BERT el modelo lingüístico más avanzado para NPL.Descubre BERT (Representación de Codificador Bidireccional de Transformadores), un modelo linguístico basado en redes neuronales para el pre-entrenamiento del procesamiento del lenguaje natural, creado y publicado en 2018 por Jacob Devlin y sus compañeros en Google.
Un texto original escrito por Rani Horev y publicado en https://towardsdatascience.com
BERT (Bidirectional Encoder Representations from Transformers) es un reciente documento técnico publicado por investigadores de Google AI Language. Ha causado un gran revuelo en la comunidad de Aprendizaje Automático al presentar resultados de vanguardia en una amplia variedad de tareas PNL, como la respuesta a preguntas (SQuAD v1.1), inferencia del lenguaje natural (MNLI) y otras muchas.
La principal innovación técnica de BERT es la aplicación del entrenamiento bidireccional de Transformer, un popular modelo de atención, al modelado del lenguaje. Esto contrasta con los esfuerzos anteriores, que examinaban una secuencia de texto de izquierda a derecha o combinaban el entrenamiento de izquierda a derecha y de derecha a izquierda. Los resultados del artículo demuestran que un modelo lingüístico entrenado bidireccionalmente puede tener un sentido más profundo del contexto y el flujo del lenguaje que los modelos lingüísticos de una sola dirección. En el artículo, los investigadores detallan una novedosa técnica denominada Masked LM (MLM) que permite el entrenamiento bidireccional en modelos en los que antes era imposible.
Disclaimer: Esta es una traducción gratuita no profesional realizada por un traductor amateur. Si necesitas traducciones técnicas de artículos científicos o servicios lingüísticos de cualquier tipo, es mejor que contactes con nuestra agencia de traducción en Madrid o nuestra oficina de traducción en Barcelona. Ibidem Group es una red de empresas de traducción con traductores profesionales de idiomas en todo el mundo.
INDICE
Antecedentes
En el campo de la visión por ordenador, los investigadores han demostrado repetidamente el valor del aprendizaje por transferencia, es decir, el preentrenamiento de un modelo de red neuronal en una tarea conocida, por ejemplo, ImageNet, y la posterior puesta a punto, utilizando la red neuronal entrenada como base de un nuevo modelo de propósito específico. En los últimos años, los investigadores han demostrado que una técnica similar puede ser útil en muchas tareas de lenguaje natural.
Un enfoque diferente, que también es popular en las tareas de PNL y que se ejemplifica en el reciente documento ELMo, es el entrenamiento basado en características. En este enfoque, una red neuronal preentrenada produce incrustaciones de palabras que luego se utilizan como características en los modelos de PNL.
Cómo funciona BERT
BERT utiliza Transformer, un mecanismo de atención que aprende las relaciones contextuales entre las palabras (o subpalabras) de un texto. En su forma simple, Transformer incluye dos mecanismos separados: un codificador que lee el texto de entrada y un decodificador que produce una predicción para la tarea. Dado que el objetivo de BERT es generar un modelo lingüístico, sólo es necesario el mecanismo codificador. El funcionamiento detallado de Transformer se describe en un documento de Google.
A diferencia de los modelos direccionales, que leen la entrada de texto secuencialmente (de izquierda a derecha o de derecha a izquierda), el codificador Transformer lee toda la secuencia de palabras a la vez. Por eso se considera bidireccional, aunque sería más exacto decir que es no direccional. Esta característica permite al modelo aprender el contexto de una palabra basándose en todo su entorno (izquierda y derecha de la palabra).
El gráfico siguiente es una descripción de alto nivel del codificador Transformer. La entrada es una secuencia de tokens, que primero se incrustan en vectores y luego se procesan en la red neuronal. La salida es una secuencia de vectores de tamaño H, en la que cada vector corresponde a un token de entrada con el mismo índice.
Cuando se entrenan modelos lingüísticos, existe el reto de definir un objetivo de predicción. Muchos modelos predicen la siguiente palabra de una secuencia (por ejemplo, «El niño llegó a casa de ___»), un enfoque direccional que limita intrínsecamente el aprendizaje del contexto. Para superar este reto, BERT utiliza dos estrategias de entrenamiento:
LM enmascarado (MLM)
Antes de introducir las secuencias de palabras en el BERT, el 15% de las palabras de cada secuencia se sustituye por un token [MASK]. A continuación, el modelo intenta predecir el valor original de las palabras enmascaradas, basándose en el contexto proporcionado por las demás palabras no enmascaradas de la secuencia. En términos técnicos, la predicción de las palabras de salida requiere:
- Añadir una capa de clasificación sobre la salida del codificador.
- Multiplicar los vectores de salida por la matriz de incrustación, transformándolos en la dimensión del vocabulario.
- Cálculo de la probabilidad de cada palabra en el vocabulario con softmax.
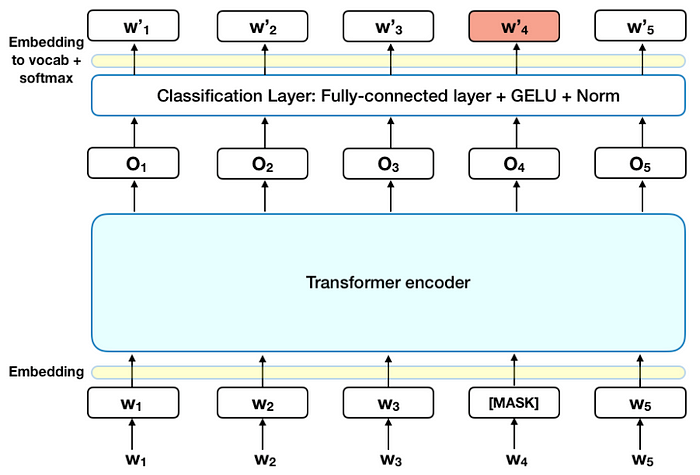
La función de pérdida BERT sólo tiene en cuenta la predicción de los valores enmascarados e ignora la predicción de las palabras no enmascaradas. Como consecuencia, el modelo converge más lentamente que los modelos direccionales, una característica que se ve compensada por su mayor conocimiento del contexto (véase el punto 3).
Nota: En la práctica, la implementación del BERT es ligeramente más elaborada y no sustituye todas las palabras enmascaradas del 15%. Véase el Apéndice A para más información.
Predicción de la siguiente frase (NSP)
En el proceso de entrenamiento del BERT, el modelo recibe pares de frases como entrada y aprende a predecir si la segunda frase del par es la siguiente del documento original. Durante el entrenamiento, el 50% de las entradas son un par en el que la segunda frase es la frase posterior del documento original, mientras que en el otro 50% se elige una frase aleatoria del corpus como segunda frase. Se supone que la frase aleatoria estará desconectada de la primera frase.
Para ayudar al modelo a distinguir entre las dos frases en el entrenamiento, la entrada se procesa de la siguiente manera antes de entrar en el modelo:
- Se inserta una ficha [CLS] al principio de la primera frase y una ficha [SEP] al final de cada frase.
- A cada token se le añade una incrustación de frase que indica la frase A o la frase B. Las incrustaciones de frases son similares a las incrustaciones de tokens con un vocabulario de 2.
- Se añade una incrustación posicional a cada ficha para indicar su posición en la secuencia. El concepto y la implementación de la incrustación posicional se presentan en el documento Transformer.
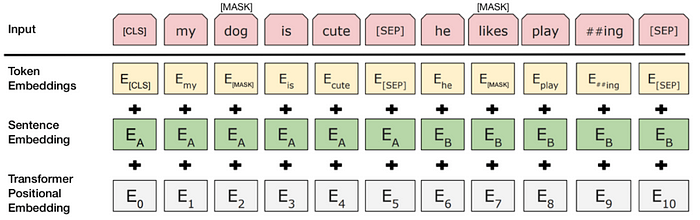
Fuente: BERT [Devlin et al., 2018], con modificaciones.
Para predecir si la segunda frase está efectivamente conectada con la primera, se realizan los siguientes pasos:
- Toda la secuencia de entrada pasa por el modelo Transformer.
- La salida del token [CLS] se transforma en un vector de forma 2×1, utilizando una capa de clasificación simple (matrices aprendidas de pesos y sesgos).
- Cálculo de la probabilidad de IsNextSequence con softmax.
Cuando se entrena el modelo BERT, la LM enmascarada y la predicción de la siguiente frase se entrenan juntas, con el objetivo de minimizar la función de pérdida combinada de las dos estrategias.
Cómo utilizar BERT (ajustes)
Utilizar el BERT para una tarea específica es relativamente sencillo:
BERT puede utilizarse para una gran variedad de tareas lingüísticas, añadiendo sólo una pequeña capa al modelo central:
- Las tareas de clasificación, como el análisis de sentimientos, se realizan de forma similar a la clasificación de frases siguientes, añadiendo una capa de clasificación sobre la salida del transformador para el token [CLS].
- En las tareas de respuesta a preguntas (por ejemplo, SQuAD v1.1), el software recibe una pregunta relativa a una secuencia de texto y debe marcar la respuesta en la secuencia. Mediante BERT, se puede entrenar un modelo de preguntas y respuestas aprendiendo dos vectores adicionales que marcan el principio y el final de la respuesta.
- En el reconocimiento de entidades con nombre (NER), el software recibe una secuencia de texto y se le pide que marque los distintos tipos de entidades (persona, organización, fecha, etc.) que aparecen en el texto. Utilizando el BERT, se puede entrenar un modelo NER alimentando el vector de salida de cada token en una capa de clasificación que predice la etiqueta NER.
En el entrenamiento de ajuste fino, la mayoría de los hiperparámetros son los mismos que en el entrenamiento BERT, y el documento ofrece una guía específica (Sección 3.5) sobre los hiperparámetros que requieren ajuste. El equipo del BERT ha utilizado esta técnica para obtener resultados de vanguardia en una amplia variedad de tareas de lenguaje natural, detalladas en la sección 4 del documento.
Conclusiones
- El tamaño del modelo importa, incluso a gran escala. BERT_large, con 345 millones de parámetros, es el mayor modelo de su clase. En las tareas a pequeña escala es manifiestamente superior a BERT_base, que utiliza la misma arquitectura con «sólo» 110 millones de parámetros.
- Con suficientes datos de entrenamiento, a más pasos de entrenamiento, mayor precisión. Por ejemplo, en la tarea MNLI, la precisión de BERT_base mejora en un 1,0% cuando se entrena con un lote de 1M de pasos (128.000 palabras de tamaño de lote) en comparación con 500K pasos con el mismo tamaño de lote.
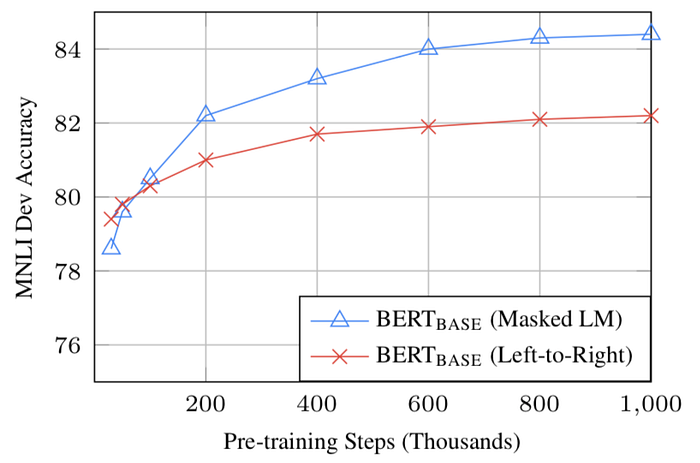
- El enfoque bidireccional de BERT (MLM) converge más lentamente que los enfoques de izquierda a derecha (porque sólo se predice el 15% de las palabras en cada lote), pero el entrenamiento bidireccional sigue superando al entrenamiento de izquierda a derecha tras un pequeño número de pasos de preentrenamiento.
Consideraciones computacionales (entrenamiento y aplicación)

Conclusión
BERT es sin duda un avance en el uso del aprendizaje automático para el procesamiento del lenguaje natural. El hecho de que sea accesible y permita un rápido ajuste fino permitirá probablemente una amplia gama de aplicaciones prácticas en el futuro. En este resumen, hemos intentado describir las ideas principales del artículo sin ahogarnos en excesivos detalles técnicos. Para quienes deseen profundizar en el tema, recomendamos encarecidamente la lectura del artículo completo y de los artículos complementarios a los que se hace referencia en él. Otra referencia útil es el código fuente y los modelos de BERT, que cubren 103 lenguajes y fueron generosamente liberados como código abierto por el equipo de investigación.
Apéndice A – Enmascaramiento de palabras
El entrenamiento del modelo lingüístico en BERT se realiza mediante la predicción del 15% de los tokens de la entrada, que fueron elegidos al azar. Estos tokens se preprocesan de la siguiente manera: el 80% se sustituye por un token «[MASK]», el 10% por una palabra aleatoria y el 10% utiliza la palabra original. La intuición que llevó a los autores a elegir este enfoque es la siguiente (gracias a Jacob Devlin, de Google, por la intuición):
- Si utilizáramos [MASK] el 100% de las veces, el modelo no produciría necesariamente buenas representaciones de tokens para las palabras no enmascaradas. Los tokens no enmascarados se seguían utilizando para el contexto, pero el modelo estaba optimizado para predecir las palabras enmascaradas.
- Si utilizamos [MÁSCARA] el 90% de las veces y palabras al azar el 10%, esto enseñaría al modelo que la palabra observada nunca es correcta.
- Si utilizáramos [MASK] el 90% de las veces y mantuviéramos la misma palabra el 10% de las veces, entonces el modelo podría copiar trivialmente la incrustación no contextual.
No se realizó ninguna ablación de las proporciones de este enfoque, y puede haber funcionado mejor con diferentes proporciones. Además, el rendimiento del modelo no se probó simplemente enmascarando el 100% de las fichas seleccionadas.
Para ver más resúmenes sobre las recientes investigaciones de aprendizaje automático, consulte Lyrn.AI.
Articulos relacionados
Breve introducción a BERT el modelo lingüístico más avanzado para Procesamiento de lenguaje (NLP) y Traducción Automática (MT), de la mano de Rani Horev.
Breve introducción a BERT el modelo lingüístico más avanzado para Procesamiento de lenguaje (NLP) y Traducción Automática (MT), de la mano de Rani Horev.

Traducción a Español de un artículo en Inglés de Teven Le Scao explicando los paradigmas y la evolución histórica de la Traducción Automática (MT): desde sus orígenes en 1933, y la posterior Traducción Automática basada en reglas, hasta la Traducción Automática basada en...