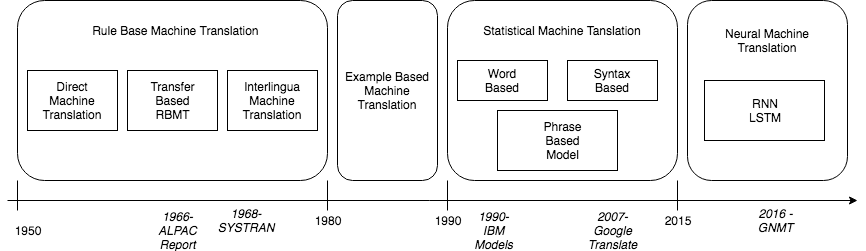
Evolución de la traducción automática.
Traducción a Español de un artículo en Inglés de Some Aditya Mandal donde se explican los esfuerzos de los investigadores que hicieron avanzar la Traducción Automática Estadística hasta la actual Traducción Automática Neuronal.
 15 junio, 2021 De la traducción automática estadística a la neuronal
15 junio, 2021 De la traducción automática estadística a la neuronalTraducción de Mauri, traductor ingles – español experto en Machine Translation.
Texto original escrito por Some Aditya Mandal y publicado en towardsdatascience.com
***
En 1949, Warren Weaver, investigador de la Fundación Rockefeller, presentó una serie de propuestas de traducción automática basadas en la teoría de la información y en los éxitos obtenidos en el descifrado de códigos durante la Segunda Guerra Mundial.
Al cabo de unos años, la investigación sobre la traducción automática comenzó en serio en muchas universidades estadounidenses. Tal y como describe el Informe Hutchins, el 7 de enero de 1954 comenzó el experimento Georgetown-IBM, el ordenador IBM 701 tradujo automáticamente al Inglés 60 frases en Ruso, por primera vez en la historia. Fue la primera demostración pública de un sistema de traducción automática y suscitó un gran interés entre los medios de comunicación y el público.
Disclaimer: Este es un ejercicio de traducción realizado por un estudiante de traducción en prácticas. Si lo que necesitas son servicios de traducción profesional, contacta con la agencia de traducción Ibidem Group, que ofrece tanto traducciones en Barcelona como traducciones en Madrid.
El informe ALPAC afirmaba que las máquinas no pueden competir con la calidad de la traducción humana y sugería que se dejara de financiar la traducción automática. Sin embargo, varios investigadores siguieron estudiando cómo utilizar la máquina para crear traducciones automáticas de idiomas. La mayoría de estas investigaciones se concentraron en pares de idiomas limitados con entradas limitadas y motores basados en reglas. En la década de 1980, se utilizaba un número importante de motores de traducción automática que se basaban en tecnologías de mainframe, como SYSTRAN, Logos, etc.
INDICE
Traducción automática estadística
Brown et alia (1990) propusieron el uso de métodos estadísticos en las traducciones automáticas. Propusieron un proceso de traducción en el que el texto de origen se divide en un conjunto de ubicaciones fijas, luego se utiliza el glosario para seleccionar el conjunto de ubicaciones fijas para crear una secuencia y, por último, las palabras en las ubicaciones fijas de destino se reorganizan para formar una frase de destino. Desarrollaron con éxito las técnicas estadísticas para la creación automática de glosarios y la ordenación de las secuencias de palabras de destino, pero no proporcionaron ejemplos de oraciones traducidas.
Brown et alia (1993) describieron una serie de cinco modelos estadísticos para el proceso de traducción y dieron algoritmos para estimar los parámetros de estos modelos dado un conjunto de pares de frases bilingües. Estos modelos se consideraron posteriormente como los modelos de alineación de IBM. Definieron el concepto de alineación palabra por palabra entre el par de frases bilingües. Su algoritmo asignaba una probabilidad a cada una de estas alineaciones palabra por palabra para cualquier par de frases. Aunque su investigación se limitó a traducciones menores del inglés y el francés, supuso una mejora considerable de la alineación de las relaciones palabra por palabra en el par de frases.

Vogel et alia (1996) describieron un nuevo modelo para la alineación de palabras en la Traducción Automática Estadística utilizando un Modelo de Markov Oculto de primer orden, ya que resolvía el problema de la alineación temporal para el reconocimiento del habla. La idea principal del modelo era hacer que las probabilidades de alineación palabra por palabra dependieran de las posiciones de alineación en lugar de las posiciones absolutas. El modelo basado en HMM produjo probabilidades de traducción a la par que el modelo de alineación de mezcla y las alineaciones de posición fueron mucho más suaves en el modelo basado en HMM.
Och et alia (1999) describieron un método para determinar las clases de palabras bilingües que se utilizan en la traducción automática estadística. Desarrollaron un criterio de optimización basado en el enfoque de máxima probabilidad y describieron además un algoritmo de agrupación. Los resultados de sus experimentos mostraron que el uso de clases de palabras bilingües mejoraba significativamente las traducciones automáticas estadísticas.
Yamada et alia (2001) propusieron un modelo de traducción estadística basado en la sintaxis. Su modelo transformaba un árbol de parseo del idioma de origen en una cadena del idioma de destino aplicando operaciones estocásticas en cada nodo. Dichas operaciones capturaban las diferencias lingüísticas, como el orden de las palabras y el marcado de mayúsculas y minúsculas. El modelo produjo alineaciones de palabras que eran mejores que las producidas por el modelo 5 de IBM.
Koehn et alia (2003) propusieron un nuevo modelo de traducción basado en frases y un algoritmo de descodificación que les permitió evaluar y comparar varios modelos de traducción basados en frases propuestos anteriormente. Diseñaron un marco uniforme para comparar otros modelos de traducción diferentes. El modelo propuesto por Koehn et. al(2003) se basó en el modelo de canal ruidoso de Brown et. al(1993) y utilizaron la regla de Bayes para reformular la probabilidad de traducción de una frase extranjera en francés al inglés.
Chiang et alia (2005) presentaron un modelo de traducción automática basado en frases que utilizaba frases jerárquicas -frases que contenían subfrases- y propusieron el uso de frases jerárquicas que consistían tanto en palabras como en subfrases para abordar este problema. Su modelo se basaba en una gramática libre de contexto sincrónica ponderada. El modelo construía traducciones parciales utilizando las frases jerárquicas y luego las combinaba en serie en un modelo estándar basado en frases. En lugar de utilizar el enfoque tradicional de canales ruidosos, utilizaron un modelo log-lineal más general.
Traducción automática neuronal
En 2013, Kalchbrennery Blunsom(2013) propusieron una nueva estructura de codificador-decodificador de extremo a extremo para la traducción automática. Introdujeron una clase de modelos probabilísticos de traducción continua denominados Modelos de Traducción Continua Recurrente, que se basaban exclusivamente en representaciones continuas de palabras, frases y oraciones y no se basaban en alineaciones o unidades de traducción frasal.
Sutskeveret al.(2014) propusieron el uso de redes neuronales profundas en el aprendizaje secuencia a secuencia para las traducciones automáticas. Su método utilizó una memoria a corto plazo de varias capas (LSTM) para asignar la secuencia de entrada a un vector de dimensiones fijas y, a continuación, utilizó otra LSTM profunda para descodificar la secuencia de destino a partir del vector. Sus resultados demostraron que un sistema de traducción automática neural con una LSTM profunda de gran tamaño y un vocabulario limitado puede superar a un sistema estándar basado en SMT.

Cho et. al (2014) propusieron un nuevo modelo de red neuronal con dos redes neuronales recurrentes (RNN) como codificador y decodificador. Una RNN codifica una secuencia de símbolos en una representación vectorial de longitud fija, mientras que la otra decodifica la representación en otra secuencia de símbolos. Sus resultados mostraron que la RNN codificadora-decodificadora era capaz de capturar tanto las estructuras semánticas como sintácticas de las frases.
Bahdanauet. al (2014) propusieron un método que permitía que un modelo buscara automáticamente partes de una frase de origen que fueran relevantes para predecir una palabra de destino, sin tener que formar estas partes como un segmento duro explícitamente. Con este enfoque, lograron un rendimiento de traducción comparable al del sistema de última generación basado en frases en la tarea de traducción del inglés al francés.
Luong et. al (2015) propusieron dos clases efectivas de mecanismos de atención, un enfoque global que siempre atiende a todas las palabras de origen y uno local que solo mira un subconjunto de palabras de origen a la vez.Su modelo de conjunto utilizando diferentes arquitecturas de atención estableció un nuevo resultado del estado del arte en la tarea de traducción de inglés a alemán WMT’15 con 25,9 puntos BLEU.
Jozefowiczet. al (2016) experimentaron con diferentes modelos de redes neuronales en diferentes tamaños de corpus, sus experimentos mostraron que las RNN pueden ser entrenadas en grandes cantidades de datos, y superan a los modelos de la competencia, incluyendo N-gramas cuidadosamente ajustados. Sus experimentos mostraron que una LSTM LM grande y regularizada, con capas de proyección y entrenada con una aproximación al Softmax verdadero con muestreo de importancia se desempeñó mucho mejor que los N-gramas.
En los resultados de la Primera Conferencia sobre Traducción Automática (WMT’16), los sistemas de traducción automática neural que participaron en la evaluación de la WMT superaron al sistema de traducción automática estadística basado en frases en hasta 3 puntos BLEU (Bojar et. al 2016).
Philip Koehn escribió: «La traducción automática neural (NMT) es un nuevo enfoque emocionante y prometedor de la traducción automática. Sin embargo, aunque la tecnología es prometedora, aún nos queda camino por recorrer hasta llegar a implementaciones comerciales que puedan rivalizar con la traducción automática basada en reglas (RBMT) y la traducción automática estadística (SMT) en todos los casos de uso. Algunas afirmaciones recientes de los actores del sector que sugieren que la calidad casi humana está a la vuelta de la esquina para todos nosotros, podrían ser un poco simplificadas». Argumentó que, aunque los sistemas de traducción automática neural produzcan resultados de calidad superior, es muy difícil implantar estos sistemas a escala industrial, ya que se necesitaría una enorme inversión en infraestructura para procesar las traducciones.
La traducción automática neuronal de Google
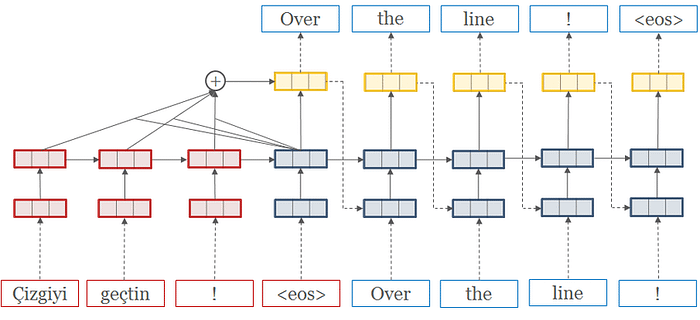
Wu et al (2016) propusieron un modelo que sigue el marco común de aprendizaje secuencia a secuencia Sutskever.(2014) con atención Bahdanauet. al (2014). El modelo tiene tres componentes: una red codificadora, una red decodificadora y una red de atención. La red codificadora convierte una frase fuente en una lista de vectores, un vector por símbolo de entrada. Cuando esta lista de vectores se pasa a la red decodificadora, ésta produce un símbolo cada vez hasta que encuentra el símbolo especial de fin de frase (EOS). El codificador y el descodificador están conectados a través de un módulo de atención que permite al descodificador centrarse en diferentes regiones de la frase fuente durante el curso de la descodificación.
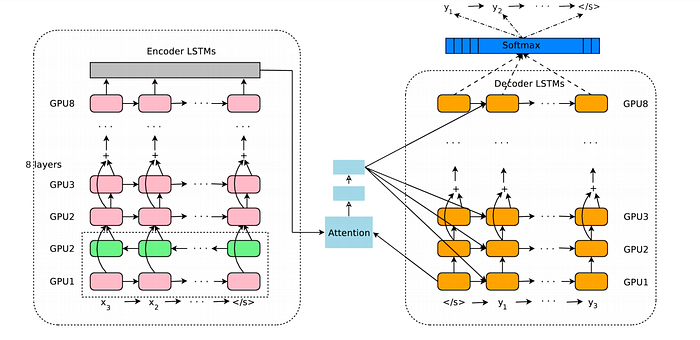
La descripción de la arquitectura de Wu et al (2016) es la siguiente. A la izquierda está la red codificadora, a la derecha la red decodificadora y en el centro el módulo de atención. La capa inferior del codificador es bidireccional: los nodos rosas recogen información de izquierda a derecha, mientras que los nodos verdes recogen información de derecha a izquierda. Las otras capas del codificador son unidireccionales. Las conexiones residuales parten de la tercera capa desde abajo en el codificador y el decodificador. El modelo se divide en varias GPU para acelerar el entrenamiento. En su configuración, tienen 8 capas LSTM de codificación (1 capa bidireccional y 7 capas unidireccionales) y 8 capas de decodificación. Con esta configuración, una réplica del modelo se divide en 8 partes y se coloca en 8 GPUs diferentes que suelen pertenecer a una misma máquina. Durante el entrenamiento, las capas codificadoras bidireccionales inferiores calculan primero en paralelo. Una vez que ambas terminan, las capas codificadoras unidireccionales comienzan a computar, cada una en una GPU distinta. Para mantener el mayor paralelismo posible durante la ejecución de las capas decodificadoras, utilizaron la salida de la capa decodificadora inferior sólo para obtener el contexto de atención recurrente, que se envía directamente a todas las capas decodificadoras restantes. La capa softmax también se particiona y se coloca en múltiples GPUs. Dependiendo del tamaño del vocabulario de salida, las hacen funcionar en las mismas GPU que las redes de codificación y decodificación, o las hacen funcionar en un conjunto separado de GPU dedicadas.

Su red decodificadora se implementa como una amalgama de una red RNN y una capa softmax. La red RNN decodificadora crea un estado oculto para el siguiente símbolo a predecir, que luego pasa por la capa softmax para generar una distribución de probabilidad sobre los símbolos de salida candidatos. En sus experimentos, los autores descubrieron que los sistemas de traducción automática neuronal deben contar con redes RNN profundas para el codificador y el decodificador a fin de lograr una buena precisión, ya que necesitan captar las diminutas irregularidades de los idiomas de origen y destino. El modelo de atención que implementaron en su investigación es similar al de Bahdanauet. al (2014).
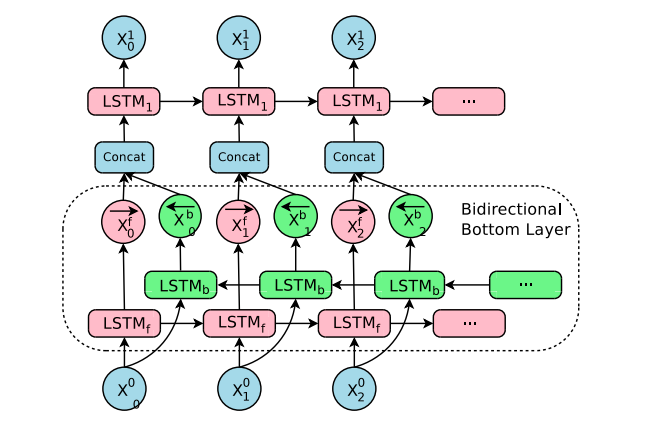
Wu et al (2016) reconocieron el hecho de que el simple hecho de añadir más capas de LSTM hace que la red sea más lenta y difícil de entrenar, probablemente debido a los problemas de explosión y desaparición del gradiente. La conexión residual mejoró en gran medida el flujo de gradiente en el paso hacia atrás, lo que les permitió entrenar sus redes codificadoras y decodificadoras con 8 capas LSTM. Utilizaron las conexiones bidireccionales para la capa codificadora inferior mientras mantenían las otras capas unidireccionales para permitir la máxima paralelización durante el cálculo.
Wu et al (2016) utilizaron dos corpus públicos WMT’14 de inglés a francés e inglés a alemán como referencia para sus sistemas de traducción automática neural. Además de estos corpus disponibles públicamente, utilizaron el corpus de producción de traducciones de Google, que es mucho más grande que el corpus WMT para un par de idiomas determinado. El WMT En->Fr contiene 36 millones de pares de frases, mientras que el En->De contiene 5 millones de pares de frases. Los autores evaluaron sus modelos mediante la realización de evaluaciones humanas en paralelo con la métrica estándar de puntuación BLEU. Las puntuaciones paralelas oscilaron entre 0 y 6. Una puntuación de 0 significa «traducción completamente sin sentido» y una puntuación de 6 significa «traducción perfecta: el significado de la traducción es completamente coherente con la fuente y la gramática es correcta». Entrenaron los modelos utilizando el sistema que implementaron en TensorFlow. Utilizaron modelos basados en palabras, en caracteres, en caracteres mixtos y varios modelos de palabras con diferentes tamaños de vocabulario para los experimentos. La tabla resume los resultados que obtuvieron en el conjunto de datos WMT En ->Fr. Su mejor modelo, WPM-32K, obtuvo una puntuación BLEU de 38,95. El WMT En ->De fue mucho más difícil que el En->Fr debido al menor tamaño de los datos de entrenamiento y a que el alemán es una lengua más rica morfológicamente que necesita vocabulario para los modelos de palabras. Su mejor modelo, WPM-32K, obtuvo una puntuación BLEU de 24,61.

Además, utilizaron el entrenamiento RL para afinar la puntuación BLEU de las frases tras el entrenamiento normal de máxima verosimilitud. Ensamblaron 8 modelos refinados con RL y obtuvieron un resultado de vanguardia de 41,6 puntos BLEU en el conjunto de datos WMT En->Fr. Obtuvieron un resultado de vanguardia de 26,30 puntos BLEU en el conjunto de datos WMT En->De. Las cuatro traducciones fueron: 1) la mejor traducción basada en frases descargada del sitio web de statmt, 2) un conjunto de 8 modelos entrenados por ML, 3) un conjunto de 8 modelos entrenados por ML y luego refinados por RL, y 4) la traducción humana de referencia obtenida directamente de los datos de prueba. Los resultados se muestran en la tabla. Los resultados muestran claramente que, aunque el refinamiento RL puede conseguir mejores puntuaciones BLEU, apenas mejora la impresión humana de la calidad de la traducción.

La NMT de Google es a día de hoy la tecnología de Traducción Automática más puntera del mundo.
Articulos relacionados
Traducción a Español de un artículo en Inglés de Some Aditya Mandal donde se explican los esfuerzos de los investigadores que hicieron avanzar la Traducción Automática Estadística hasta la actual Traducción Automática Neuronal.

Traducción a Español de un artículo en Ingles de Arslan Mirza explicando las ventajas y limitaciones de la Traducción Automática, ante los cambios constantes de la información.

Traducción a Español de un artículo en Inglés de Teven Le Scao explicando los paradigmas y la evolución histórica de la Traducción Automática (MT): desde sus orígenes en 1933, y la posterior Traducción Automática basada en reglas, hasta la Traducción Automática basada en...