Post-edición automática de textos traducidos por traducción automática
Traduccion a Español de un articulo de Amirhossein Tebbifakhr, explicando los resultados de los trabajos de la FBK en su intento por automatizar las tareas de post-edición, reduciendo así los esfuerzos de los traductores que revisan las traducciones generadas mediante Traducción Automática.
 22 junio, 2021 Post-edicion automatica de una traduccion automatica
22 junio, 2021 Post-edicion automatica de una traduccion automaticaTraducción realizada por Jose, traductor experto en post-edición de textos traducidos mediante Traducción Automática.
Texto original escrito por Amirhossein Tebbifakhr, publicado el 6/2/2019 en
https://medium.com/machine-translation-fbk/automatic-post-editing-of-machine-translated-text-274b76558856
***
Participación de la FBK en la tarea compartida de posedición automática del WMT 2018.
INDICE
Post-edición automática
Me gustaría comenzar destacando la importancia del papel de la traducción: ¿Por qué es necesaria la traducción? ¿Cuál es la situación actual de la industria de la traducción? ¿Cómo se utilizan los sistemas de traducción automática (TA) en la industria de la traducción?
Con la llegada de la globalización, también surgió el problema de la comunicación global. Según estadísticas recientes, hay más de 7.000 lenguas vivas en todo el mundo [1], y los contenidos que se publican a diario deben traducirse a todas estas lenguas para que estén disponibles para la gente de todo el mundo. Para hacerse una idea de esta necesidad, el valor actual del mercado de la traducción es de más de 46.000 millones de dólares estadounidenses y, según las estimaciones, aumentará a más de 56.000 millones en 2021 [2]. En cuanto a la traducción automática, actualmente Google traduce más de 140.000 millones de palabras al día [3], y si añadimos los demás servicios de traducción automática en línea, la cantidad total de palabras traducidas automáticamente supera los 500.000 millones.
Para hacer frente a esta enorme necesidad de traducción, las empresas buscan soluciones para reducir el esfuerzo de los traductores. Hasta hace poco, la industria de la traducción se basaba principalmente en la traducción humana, ya que el rendimiento de los sistemas de MT no era lo suficientemente bueno como para soportar el flujo de trabajo de traducción. Hoy en día, gracias a la llegada de la traducción automática neural (NMT), que ha mejorado en gran medida el rendimiento con respecto al enfoque estadístico tradicional basado en frases (PBSMT), la industria intenta cada vez más integrar los sistemas de MT en el proceso de traducción, con el fin de reducir el coste y el tiempo de traducción. Aunque los sistemas NMT muestran resultados muy prometedores, su resultado sigue necesitando ser revisado por un humano, lo que ha introducido en las empresas de traducción el concepto de «traducción como post-edición». El flujo de trabajo de la «traducción como posedición» se muestra en la figura 1: dado un texto fuente que hay que traducir, primero lo traduce un sistema de traducción automática y luego lo posedita un humano, es decir, corrige los errores cometidos por el sistema de traducción automática.
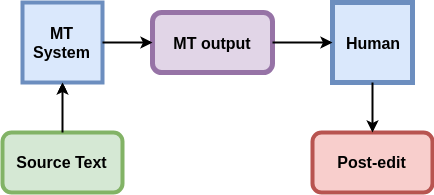
Este flujo de trabajo genera múltiple textos: el «texto de origen», el texto «resultado de la traducción automática» y el texto de la posterior «postedición humana». ¿Qué podemos hacer con estos textos / datos para mejorar aún más la calidad de la traducción automática que debe revisar el ser humano? La solución directa es explotar el «Texto de origen» y la «Post-edición humana» como nuevos datos de entrenamiento para mejorar el rendimiento del sistema de TA, lo que supone un menor esfuerzo por parte del humano para la post-edición. Pero, ¿qué ocurre si la empresa utiliza un sistema de MT de terceros, que no se puede modificar? La respuesta es desarrollar un sistema de posedición automática (APE). El objetivo de un sistema APE es corregir los errores de un resultado de MT dado y generar una traducción poseditada «similar a la humana». Por lo tanto, el APE puede describirse como una traducción monolingüe, cuyo objetivo es asignar la salida del sistema de MT a la traducción correcta.
Participación de FBK en la tarea compartida de post-edición automática
El WMT organiza anualmente una tarea compartida para poner a prueba la tecnología APE. En 2018, esta tarea compartida consistió en dos subtareas de posedición automática, una sobre la salida de un sistema PBSMT y otra sobre la salida de NMT, ambas para la dirección lingüística inglés-alemán. Nosotros -grupo de MT de la Fondazione Bruno Kessler- participamos en esta tarea compartida centrándonos en dos aspectos importantes para un sistema APE: ser rápidos en el entrenamiento y tener en cuenta el texto de origen.
Ser rápido en la formación. La rapidez en el entrenamiento y la adaptación es una característica clave para responder a las necesidades de calidad de la industria de la traducción. Un sistema APE debe ser capaz de «ingerir» rápidamente la gran cantidad de datos que se producen a diario como subproducto del flujo de trabajo de posedición para mejorar constantemente su rendimiento.
Considerar el texto de origen. Mientras que los primeros sistemas APE seguían un enfoque monolingüe al considerar únicamente el resultado de la MT, se pueden obtener mejores resultados si se tiene en cuenta también el texto de origen. De hecho, hay algunos errores en el resultado de la TA que no pueden detectarse sin tener en cuenta el texto de origen. Por ejemplo, la frase alemana «mein Haus» (EN: mi casa) parece correcta, pero si la frase de origen fuera «mi casa», la traducción correcta sería «mein Zuhaus«. En este caso, un sistema APE que ignorara la fuente habría dejado intacto el resultado subóptimo de la MT [4]. Este sencillo ejemplo muestra cómo un sistema APE bueno y fiable debe aprovechar también la información de la fuente.
En la evaluación automática de la tarea WMT APE, nuestro sistema obtuvo la primera posición en la subtarea NMT y la segunda posición en la subtarea PBSMT.
Arquitectura
Para desarrollar nuestro sistema, utilizamos la arquitectura Transformer, que es la tecnología más avanzada en NMT. Además, es rápida de entrenar porque -a diferencia de las RNN- no hay cálculo secuencial y todo se computa en paralelo. Además, para tener en cuenta el texto de origen, combinamos dos codificadores en la arquitectura Transformer para codificar tanto el texto de origen como su salida de MT. Para simplificar la arquitectura, concatenamos la salida de estos dos codificadores para alimentar el decodificador, que produce la traducción corregida. Nuestra arquitectura Transformer multifuente se muestra en la Figura 2.
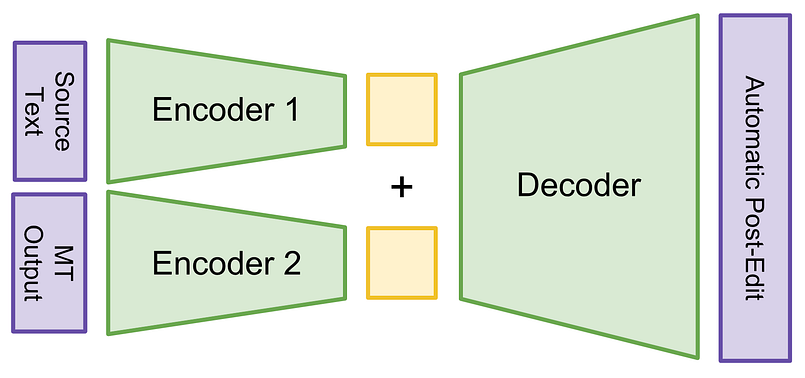
Formación
Dado que el conjunto de datos de entrenamiento publicado para la tarea compartida APE era pequeño, utilizamos dos conjuntos de datos sintéticos adicionales para preentrenar el modelo. Estos conjuntos de datos tienen la misma estructura que los datos de entrenamiento de APE (texto de origen/salida de MT/triplos de posedición), pero algunos elementos de los triples son creados artificialmente. Uno de ellos es el corpus eScape, liberado libremente por nuestro grupo, y el otro es un conjunto de datos disponible públicamente que se describe aquí. Después de alcanzar una meseta con el entrenamiento en la unión de estos dos conjuntos de datos artificiales, aplicamos dos pasos de ajuste en el conjunto de datos de entrenamiento oficial de la tarea compartida. En primer lugar, utilizamos la optimización de los parámetros de la Estimación de Máxima Verosimilitud (MLE), que es un enfoque típico en el entrenamiento de los sistemas NMT. En segundo lugar, para superar el sesgo de exposición [5] y estar en consonancia con las métricas utilizadas para clasificar los sistemas, utilizamos por primera vez el entrenamiento de riesgo mínimo (MRT) para optimizar los parámetros de nuestro sistema APE.
Resultados
Como se muestra en la Figura 3, en la subtarea PBSMT nuestro sistema APE obtuvo +8,23 BLEU sobre el resultado del sistema MT. Esta gran mejora supone reducir en gran medida el esfuerzo humano necesario con respecto a la posedición directa de la salida del sistema MT. Como esperábamos, en la subtarea NMT la ganancia del sistema APE sobre el sistema MT es menor (+0,8 BLEU). De hecho, la mejor calidad del sistema NMT en comparación con el sistema PBSMT (+12,74 BLEU), deja menos margen de mejora al sistema APE, que tiene que corregir los errores de salida del MT. Sin embargo, los resultados sugieren que, incluso en presencia de un sistema de MT de alta calidad, el sistema APE puede ayudar a reducir el esfuerzo humano de posedición.
Para esta ronda de la tarea compartida APE, nuestro sistema consistió en una única red que puede entrenarse de principio a fin, sin recurrir a conjuntos de múltiples modelos o a la concatenación de componentes que deben entrenarse de forma independiente. Estas elecciones de implementación estuvieron motivadas principalmente por las necesidades del mercado de la traducción, en el que las soluciones sencillas y fáciles de mantener son siempre preferibles a las arquitecturas complejas.
Para más detalles, consulte nuestro documento de descripción del sistema WMT-18. Déjenos un comentario o póngase en contacto con nosotros a través de nuestro correo electrónico, estaremos encantados de hablar más sobre esta dirección de trabajo.
Articulos relacionados

Traducción de un interesantísimo artículo de Jordan Kalebu explicando cómo utilizar Python para realizar traducción automática de idiomas, usando 3 bibliotecas alternativas: Goslate, Googletrans y TextBlob. Una forma super sencilla y gratuita de traducir de forma automática todos...
Traduccion a Español de un articulo de Amirhossein Tebbifakhr, explicando los resultados de los trabajos de la FBK en su intento por automatizar las tareas de post-edición, reduciendo así los esfuerzos de los traductores que revisan las traducciones generadas mediante Traducción...